Postmortem: Docker image not found
Incident report for the Logto service outage on 2023-12-17 due to loss of production Docker image.

Developer

Summary
We have experienced a service outage on 2023-12-17 due to loss of Logto production Docker image.
- Incident time: 2023-12-17 03:56:00 UTC
- Incident duration: 18 minutes
- Service impact: Logto cloud service and Logto core service were unavailable during the incident.
- Impact level: Critical
- Root cause: Logto production docker image was deleted by mistake. Failed to fetch the image from GitHub Container Registry.
Timeline
| Time | Event |
|---|---|
| Early 2023-12-17 (Specific time unknown) | Logto automated GitHub image retention workflow being executed. logto and logto-cloud production images were deleted by mistake. |
| 2023-12-17 03:56:00 UTC | Logto cloud service and Logto core service became unavailable. Incident detected by our monitoring system. |
| 2023-12-17 04:03:00 UTC | Incident acknowledged by our on-call engineer. |
| 2023-12-17 04:10:00 UTC | New deployment of Logto cloud service and Logto core service triggered with the latest image. |
| 2023-12-17 04:15:00 UTC | Logto cloud service and Logto core service became available. Incident resolved automatically |
Incident analysis
What happened
Logto service production images was deleted by our automated GitHub image retention workflow. The cloud service failed to fetch the image from GitHub Container Registry and became unavailable.
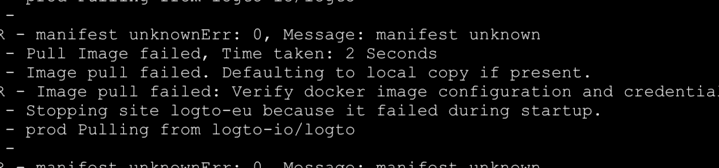
Why it happened
The automated GitHub image retention workflow deleted the production images by mistake. The workflow was designed to delete all untagged legacy images that are older than 3 days.
We tagged the production images with prod tag to identify them as production images. Whenever a production deployment being triggered, a new image with prod tag will be built and pushed to GitHub Container Registry. The prod tag will be removed from the old image after the new image is successfully built and pushed. The old image will become untagged and will be deleted by the automated GitHub image retention workflow.
Logto service image were build to support multiple architectures. The image was built with buildx and pushed to GitHub Container Registry with --platform flag. All the tags were applied to the root manifest list. The prod tag was applied to the root manifest list as well. All the sub-images listed under the multi-arch manifest list remain untagged.
Lack of careful review of the tag and manifest list structure of the Docker image, we simply configured the automated GitHub image retention workflow to delete all untagged images. The workflow deleted all the sub-images listed under the multi-arch manifest list.
Impact
This incident caused Logto cloud service and Logto core service to be unavailable for about 18 minutes. End users were unable to login to Logto and access their client applications. Logto cloud admin portal was also unavailable during the incident.
Resolution
We have stopped the automated GitHub image retention workflow and deployed a new image with prod tag to GitHub Container Registry. The new image was successfully fetched by Logto cloud service and Logto core service. The service became available again.
Lessons learned
- Never publish a workflow without careful review and testing to the production environment.
- Dry run any resource deletion job before executing it.
- Always have a backup plan for the production environment.
- Carefully define a new image retention policy.
Corrective and preventative measures
- ✅ Immediately stop the automated GitHub image retention workflow.