Unveiling URI, URL, and URN
This guide provides an overview of URI, URL, and URN, explaining their differences and use cases.

Developer

When developing web apps, we often need to call different web services. When configuring the communication and connection of different web services, we frequently encounter the concepts of URI, URL, and URN. Usually, users find it difficult to distinguish between them, leading to mixed or incorrect usage. In this article, we will provide examples and explain the differences between them to help everyone better understand these concepts and correctly interpret and use them when reading technical blogs, documentation, or communicating with other engineers.
What is a URL?
A URL (Uniform Resource Locator) provides the web address or location of resources on the internet. It is typically used to specify the location of web pages, files, or services. A URL provides a standardized format for accessing resources on the web. It is a key component of web browsing, linking, and internet communication.
A URL consists of several parts that together define the address of the resource and the protocol used to access it. Let's parse the URL below as an example and explain the function of each part one by one.
-
Scheme: This specifies the protocol or scheme used to access resources, such as HTTP (Hypertext Transfer Protocol), HTTPS (HTTP Secure), FTP (File Transfer Protocol), or others.
The scheme in the URL is
https. -
Host: Host specifies the domain name or IP address of the server that hosts the resources.
The host in the URL is
example.logto.io. -
Port: (Optional) Port represents a specific port number on the host accessing the resource. If no port is specified, it defaults to the standard port for the given scheme.
The default port for HTTP is 80, while the default port for HTTPS is 443.
The port in the URL is
8080. -
Path: (Optional) Path indicates the specific location or directory on the server where the resource is located, which can include directories and file names.
The path in the URL should be
/blogs/index.html. -
Query Parameters: (Optional) Query parameters are additional parameters passed to a resource, typically used in dynamic web applications. They appear after the path and are separated by the
?symbol.The query parameters in the URL are
params1=value1¶m2=value2, which is often represented in the form of key-value pairs, with pairs separated by the&symbol. In real usage scenarios, encoding is often required to avoid characters such as spaces. -
Fragment Identifier: (Optional) It can also be called an anchor, used to locate a specific position in the resource.
The anchor in the URL is
#introduction.
Additionally, for example, using file services or many "Contact Us" buttons on web pages are linked to URLs, such as:
ftp://documents.logto.io/files/legal/soc_ii.pdfmailto:[email protected]?subject=Enterprise%20quota%20request
What is a URI?
URI stands for "Uniform Resource Identifier". It is a string of characters that identifies a specific resource, such as a webpage, file, or service. URI provides a way to uniquely identify and locate resources using a standardized format.
A URI mainly consists of two components:
- Scheme: Indicates the protocol or scheme used to access the resource.
- Resource Identifier: Identifies the specific resource being accessed or referenced. The format of the resource identifier depends on the scheme used.
From a grammatical perspective, URIs mostly follow the same format as URLs, as specified in RFC 3986.
Although this URI format is similar to that of URLs, it does not guarantee access to any resource on the Web. Using this format can reduce namespace name conflicts.
In the section above, we introduced URLs, which not only identify a resource but also help locate that resource. So, in fact, URLs are a proper subset of URIs.
What is a URN?
URN may not be as common as URL and URI. It stands for "Uniform Resource Name", and its scope is to identify resources in a persistent manner, even if such resources no longer exist.
Unlike a URL, a URN does not provide any information on how to locate the resource; it merely identifies it, much like a pure URI. Specifically, a URN is a type of URI with the scheme "urn" and has the following structure, as described in RFC 2141:
<URN>:<NID>:<NSS>
- URN: Usually
urn. - Namespace Identifier (NID): Represents a unique namespace or identifier system that defines and manages the URN. It provides context and ensures the uniqueness of the identifier. Examples of namespaces include ISBN (International Standard Book Number), etc.
- Namespace Specific String (NSS): It is a string of characters that uniquely identifies a resource within the specified namespace. The identifier itself does not convey any information about the location or access method of the resource.
For example, a very famous book introducing computer systems CSAPP has its ISBN number represented as URN urn:isbn:9780134092669.
URNs are often used in various standard protocols, such as the assertion in the SAML protocol, which corresponds to the URN urn:oasis:names:tc:SAML:2.0:assertion.
In software engineering, we can also define URNs for specific purposes in our own systems according to the URN naming rules. For instance, in Logto, to enable Organization, you need to add the urn:logto:scope:organizations scope in the config when using the SDK. Each Organization also has its own dedicated URN urn:logto:organization:{orgId}.
Conclusion
The relationship between URI, URL, and URN can be illustrated using the following Venn diagram:
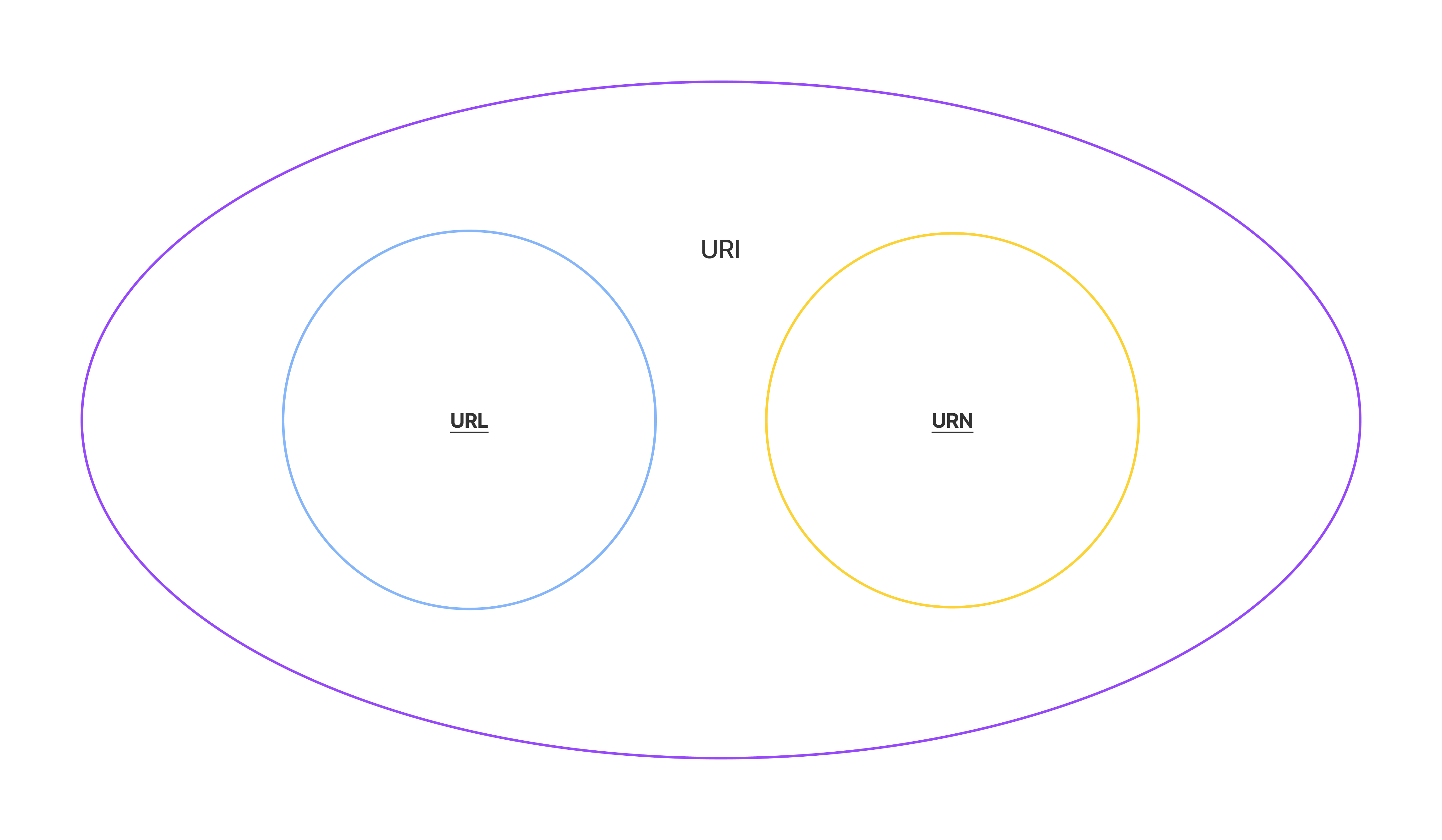
URI, URL, and URN can all be used to identify different resources, but only URL can precisely locate the position of the resource.
URI and URL can support various schemes, such as HTTP, HTTPS, FTP, but URN can be considered to only support the urn scheme.
All URLs or URNs are URIs, but not all URIs are URLs or URNs.