Postmortem : Image Docker non trouvée
Rapport d'incident pour l'arrêt du service Logto le 2023-12-17 en raison de la perte de l'image Docker de production.

Developer

Résumé
Nous avons connu une interruption de service le 2023-12-17 en raison de la perte de l'image Docker de production de Logto.
- Heure de l'incident : 2023-12-17 03:56:00 UTC
- Durée de l'incident : 18 minutes
- Impact sur le service : Le service cloud Logto et le service central Logto ont été indisponibles pendant l'incident.
- Niveau d'impact : Critique
- Cause principale : L'image Docker de production de Logto a été supprimée par erreur. Impossible de récupérer l'image depuis le GitHub Container Registry.
Chronologie
| Heure | Événement |
|---|---|
| Début 2023-12-17 (Heure précise inconnue) | Exécution du workflow de rétention d'image GitHub automatisé de Logto. Les images de production logto et logto-cloud ont été supprimées par erreur. |
| 2023-12-17 03:56:00 UTC | Le service cloud Logto et le service central Logto sont devenus indisponibles. Incident détecté par notre système de surveillance. |
| 2023-12-17 04:03:00 UTC | Incident reconnu par notre ingénieur de garde. |
| 2023-12-17 04:10:00 UTC | Nouveau déploiement du service cloud Logto et du service central Logto déclenché avec la dernière image. |
| 2023-12-17 04:15:00 UTC | Le service cloud Logto et le service central Logto sont devenus disponibles. Incident résolu automatiquement |
Analyse de l'incident
Ce qui s'est passé
Les images de production du service Logto ont été supprimées par notre workflow de rétention d'image GitHub automatisé. Le service cloud n'a pas pu récupérer l'image depuis le GitHub Container Registry et est devenu indisponible.
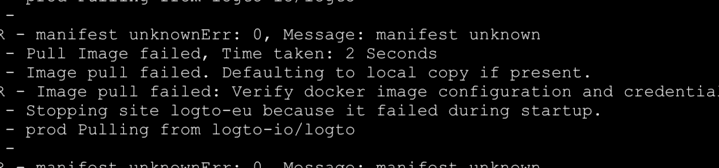
Pourquoi cela s'est produit
Le workflow de rétention d'image GitHub automatisé a supprimé les images de production par erreur. Le workflow était conçu pour supprimer toutes les images anciennes non étiquetées de plus de 3 jours.
Nous avons étiqueté les images de production avec le tag prod pour les identifier comme images de production. Chaque fois qu'un déploiement de production est déclenché, une nouvelle image avec le tag prod est construite et poussée vers le GitHub Container Registry. Le tag prod est retiré de l'ancienne image après que la nouvelle image soit construite et poussée avec succès. L'image ancienne devient non étiquetée et sera supprimée par le workflow de rétention d'image GitHub automatisé.
Les images du service Logto ont été construites pour prendre en charge plusieurs architectures. L'image a été construite avec buildx et poussée vers le GitHub Container Registry avec l'option --platform. Tous les tags ont été appliqués à la liste de manifeste principale. Le tag prod a été appliqué à la liste de manifeste principale également. Tous les sous-images répertoriées sous la liste de manifeste multi-arch restent non étiquetées.
Manque de vérification minutieuse de la structure des tags et de la liste de manifeste de l'image Docker, nous avons simplement configuré le workflow de rétention d'image GitHub automatisé pour supprimer toutes les images non étiquetées. Le workflow a supprimé toutes les sous-images listées sous la liste de manifeste multi-arch.
Impact
Cet incident a causé l'indisponibilité du service cloud Logto et du service central Logto pendant environ 18 minutes. Les utilisateurs finaux n'ont pas pu se connecter à Logto ni accéder à leurs applications clients. Le portail d'administration cloud Logto était également indisponible pendant l'incident.
Résolution
Nous avons arrêté le workflow de rétention d'image GitHub automatisé et déployé une nouvelle image avec le tag prod vers le GitHub Container Registry. La nouvelle image a été récupérée avec succès par le service cloud Logto et le service central Logto. Le service est redevenu disponible.
Leçons apprises
- Ne jamais publier un workflow sans vérification minutieuse et tests dans l'environnement de production.
- Effectuer une simulation de toute suppression de ressource avant de l'exécuter.
- Avoir toujours un plan de sauvegarde pour l'environnement de production.
- Définir soigneusement une nouvelle politique de rétention d'image.
Mesures correctives et préventives
- ✅ Arrêter immédiatement le workflow de rétention d'image GitHub automatisé.