PostgreSQL 를 사용한 멀티 테넌시 구현: 간단한 실제 예제로 배우기
PostgreSQL 행 수준 보안 (RLS) 및 데이터베이스 역할을 통해 테넌트 간의 안전한 데이터 격리를 위한 멀티 테넌트 아키텍처를 구현하는 방법을 실제 예제를 통해 배워보세요.

Developer

이전의 몇몇 기사에서 우리는 멀티 테넌시의 개념과 제품 및 실제 비즈니스 시나리오에서의 적용에 대해 깊이 탐구했습니다.
이 기사에서는 기술적 관점에서 PostgreSQL 을 사용하여 애플리케이션의 멀티 테넌트 아키텍처를 구현하는 방법을 탐구할 것입니다.
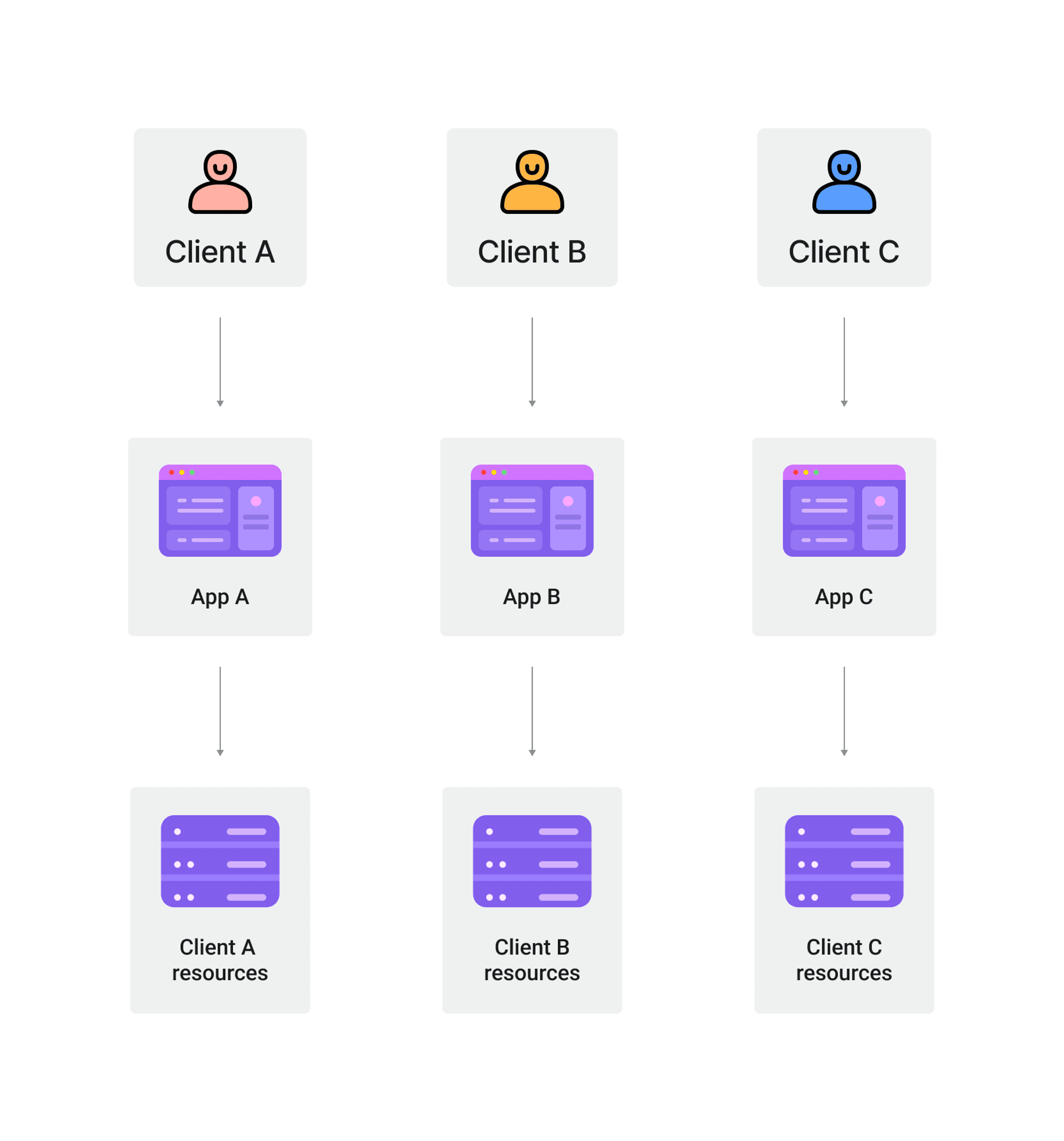
싱글 테넌트 아키텍처란 무엇인가?
싱글 테넌트 아키텍처는 각 고객이 애플리케이션 및 데이터베이스의 자체 전용 인스턴스를 갖는 소프트웨어 아키텍처를 나타냅니다.
이 아키텍처에서는 각 테넌트의 데이터와 리소스가 다른 테넌트와 완전히 격리됩니다.
멀티 테넌트 아키텍처란 무엇인가?
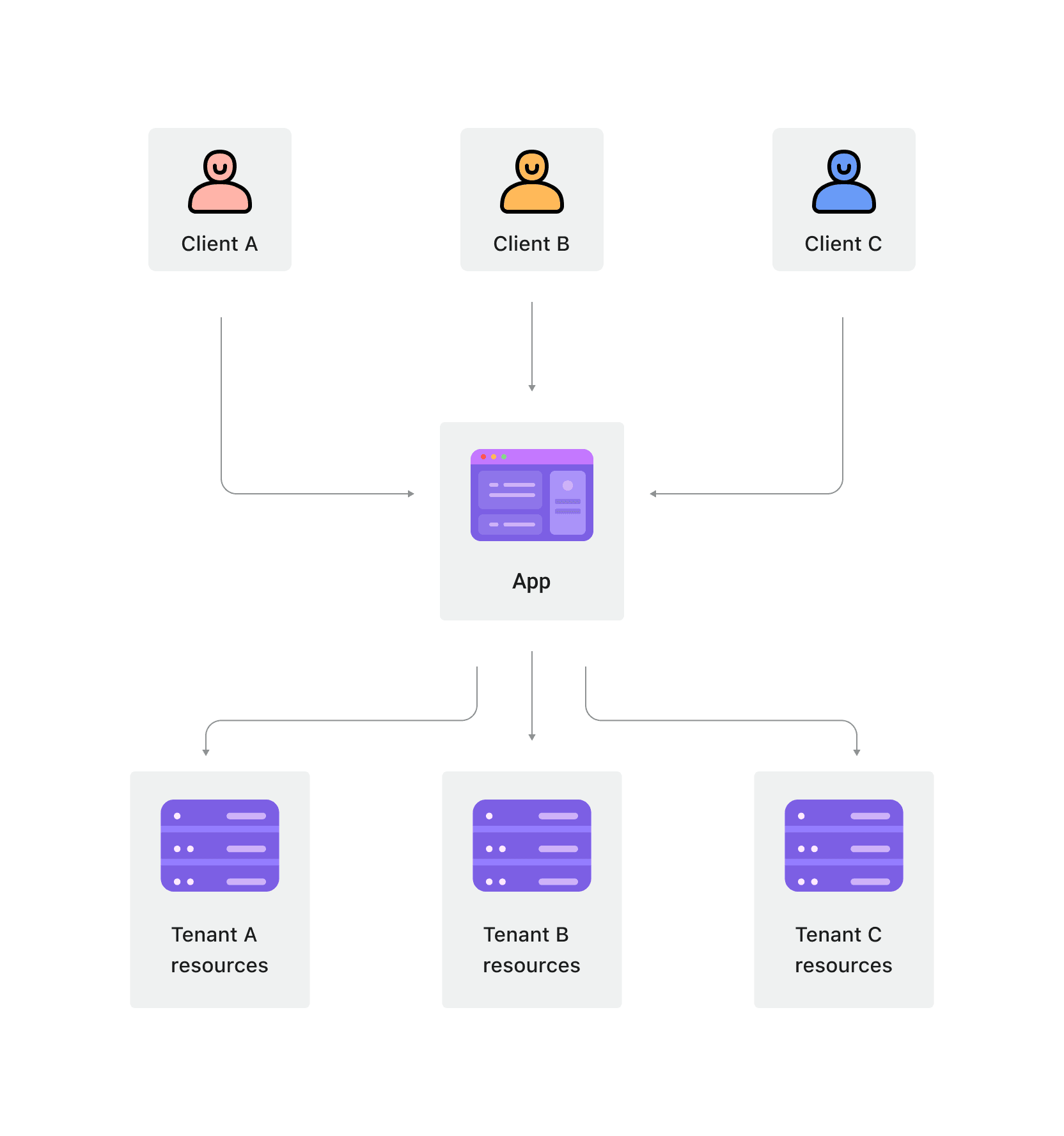
멀티 테넌트 아키텍처는 여러 고객(테넌트)이 데이터 격리를 유지하면서 동일한 애플리케이션 인스턴스 및 인프라를 공유하는 소프트웨어 아키텍처입니다. 이 아키텍처에서는 소프트웨어의 단일 인스턴스가 여러 테넌트를 제공하며 각 테넌트의 데이터는 다양한 격리 메커니즘을 통해 다른 테넌트와 분리됩니다.
싱글 테넌트 아키텍처 vs 멀티 테넌트 아키텍처
싱글 테넌트 아키텍처와 멀티 테넌트 아키텍처는 데이터 격리, 리소스 활용, 확장성, 관리 및 유지보수, 보안 등의 측면에서 다릅니다.
싱글 테넌트 아키텍처에서는 각 고객이 독립된 데이터 공간을 가지며, 리소스 활용도가 낮지만, 상대적으로 맞춤화가 더 간단합니다. 일반적으로, 특정 고객의 요구에 맞춘 싱글 테넌트 소프트웨어는 특정 직물 공급자를 위한 재고 시스템이나 개인 블로그 웹앱과 같이 사용자 요구에 맞춰지게 됩니다. 이들의 공통점은 각 고객이 애플리케이션 서비스의 독립된 인스턴스를 차지하며, 요구 사항에 맞춰 커스터마이즈를 용이하게 만든다는 것입니다.
멀티 테넌트 아키텍처에서는 다수의 테넌트가 동일한 기본 리소스를 공유하여 더 높은 리소스 활용을 얻습니다. 하지만 데이터 격리 및 보안 보장이 중요합니다.
멀티 테넌트 아키텍처는 서비스 제공자가 다양한 고객에게 표준화된 서비스를 제공할 때 선호되는 소프트웨어 아키텍처입니다. 이들 서비스는 일반적으로 낮은 수준의 커스터마이징을 가지고 있으며 모든 고객이 동일한 애플리케이션 인스턴스를 공유합니다. 애플리케이션이 업데이트될 때, 하나의 애플리케이션 인스턴스를 업데이트하는 것은 모든 고객을 위한 애플리케이션을 업데이트하는 것과 같습니다. 예를 들어, CRM(고객 관계 관리)은 표준화된 요구입니다. 이 시스템은 일반적으로 멀티 테넌트 아키텍처를 사용하여 모든 테넌트에게 동일한 서비스를 제공합니다.
멀티 테넌트 아키텍처에서 테넌트 데이터 격리 전략
멀티 테넌트 아키텍처에서는 모든 테넌트가 동일한 기본 리소스를 공유하므로, 테넌트 간 리소스의 격리가 중요합니다. 이 격리는 물리적일 필요는 없으며, 테넌트 간 리소스가 서로 보이지 않도록 보장하기만 하면 됩니다.
아키텍처 설계에서, 테넌트 간 다양한 수준의 자원 격리를 달성할 수 있습니다:

일반적으로, 테넌트 간의 공유 자원이 많을수록 시스템 반복 및 유지보수 비용이 적게 듭니다. 반대로 공유 자원이 적을수록 비용이 높아집니다.
실제 예제로 시작하는 멀티 테넌트 구현
이 기사에서는 CRM 시스템을 예로 들어 간단하면서도 실용적인 멀티 테넌트 아키텍처를 소개합니다.
모든 테넌트가 동일한 표준 서비스를 사용한다고 인식하여, 모든 테넌트가 동일한 기본 리소스를 공유하도록 결정했으며, PostgreSQL 의 행 수준 보안을 사용하여 데이터베이스 수준에서 테넌트 간의 데이터 격리를 구현할 것입니다.
또한, 각 테넌트를 위한 별도의 데이터 연결을 생성하여 테넌트 권한 관리를 더 용이하게 할 것입니다.
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape rect%2c%23mermaid-0 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg data-look='classic' id='Database' class='cluster'%3e%3crect height='332' width='259.421875' y='8' x='732.46875' style=''/%3e%3cg transform='translate(827.9296875%2c 8)' class='cluster-label'%3e%3cforeignObject height='24' width='68.5'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eDatabase%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg data-look='classic' id='subGraph0' class='cluster'%3e%3crect height='332' width='230.078125' y='8' x='260.28125' style=''/%3e%3cg transform='translate(328.203125%2c 8)' class='cluster-label'%3e%3cforeignObject height='24' width='94.234375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eCRM System%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_A_TA_0' d='M209.398%2c70L213.712%2c70C218.026%2c70%2c226.654%2c70%2c235.134%2c70C243.615%2c70%2c251.948%2c70%2c259.836%2c70C267.724%2c70%2c275.167%2c70%2c278.888%2c70L282.609%2c70'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_B_TB_1' d='M209.844%2c174L214.083%2c174C218.323%2c174%2c226.802%2c174%2c235.208%2c174C243.615%2c174%2c251.948%2c174%2c259.689%2c174C267.43%2c174%2c274.578%2c174%2c278.152%2c174L281.727%2c174'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_C_TC_2' d='M210.281%2c278L214.448%2c278C218.615%2c278%2c226.948%2c278%2c235.281%2c278C243.615%2c278%2c251.948%2c278%2c259.615%2c278C267.281%2c278%2c274.281%2c278%2c277.781%2c278L281.281%2c278'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TA_RDA_3' d='M464.031%2c70L468.419%2c70C472.807%2c70%2c481.583%2c70%2c506.147%2c70C530.711%2c70%2c571.063%2c70%2c611.414%2c70C651.766%2c70%2c692.117%2c70%2c715.94%2c70C739.763%2c70%2c747.057%2c70%2c750.704%2c70L754.352%2c70'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TB_RDB_4' d='M464.914%2c174L469.155%2c174C473.396%2c174%2c481.878%2c174%2c506.294%2c174C530.711%2c174%2c571.063%2c174%2c611.414%2c174C651.766%2c174%2c692.117%2c174%2c715.867%2c174C739.617%2c174%2c746.766%2c174%2c750.34%2c174L753.914%2c174'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TC_RDC_5' d='M465.359%2c278L469.526%2c278C473.693%2c278%2c482.026%2c278%2c506.368%2c278C530.711%2c278%2c571.063%2c278%2c611.414%2c278C651.766%2c278%2c692.117%2c278%2c715.793%2c278C739.469%2c278%2c746.469%2c278%2c749.969%2c278L753.469%2c278'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(611.4140625%2c 70)' class='edgeLabel'%3e%3cg transform='translate(-95.171875%2c -12)' class='label'%3e%3cforeignObject height='24' width='190.34375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB connection for tenant A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(611.4140625%2c 174)' class='edgeLabel'%3e%3cg transform='translate(-95.6171875%2c -12)' class='label'%3e%3cforeignObject height='24' width='191.234375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB connection for tenant B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(611.4140625%2c 278)' class='edgeLabel'%3e%3cg transform='translate(-96.0546875%2c -12)' class='label'%3e%3cforeignObject height='24' width='192.109375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB connection for tenant C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(375.3203125%2c 70)' id='flowchart-TA-0' class='node default'%3e%3crect height='54' width='177.421875' y='-27' x='-88.7109375' style='' class='basic label-container'/%3e%3cg transform='translate(-58.7109375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='117.421875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant A context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(375.3203125%2c 174)' id='flowchart-TB-1' class='node default'%3e%3crect height='54' width='179.1875' y='-27' x='-89.59375' style='' class='basic label-container'/%3e%3cg transform='translate(-59.59375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='119.1875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant B context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(375.3203125%2c 278)' id='flowchart-TC-2' class='node default'%3e%3crect height='54' width='180.078125' y='-27' x='-90.0390625' style='' class='basic label-container'/%3e%3cg transform='translate(-60.0390625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='120.078125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant C context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(109.140625%2c 70)' id='flowchart-A-3' class='node default'%3e%3crect height='54' width='200.515625' y='-27' x='-100.2578125' style='' class='basic label-container'/%3e%3cg transform='translate(-70.2578125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='140.515625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient from tenant A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(109.140625%2c 174)' id='flowchart-B-5' class='node default'%3e%3crect height='54' width='201.40625' y='-27' x='-100.703125' style='' class='basic label-container'/%3e%3cg transform='translate(-70.703125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='141.40625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient from tenant B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(109.140625%2c 278)' id='flowchart-C-7' class='node default'%3e%3crect height='54' width='202.28125' y='-27' x='-101.140625' style='' class='basic label-container'/%3e%3cg transform='translate(-71.140625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='142.28125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient from tenant C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(862.1796875%2c 70)' id='flowchart-RDA-9' class='node default'%3e%3crect height='54' width='207.65625' y='-27' x='-103.828125' style='' class='basic label-container'/%3e%3cg transform='translate(-73.828125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='147.65625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3erow data for tenant A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(862.1796875%2c 174)' id='flowchart-RDB-10' class='node default'%3e%3crect height='54' width='208.53125' y='-27' x='-104.265625' style='' class='basic label-container'/%3e%3cg transform='translate(-74.265625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='148.53125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3erow data for tenant B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(862.1796875%2c 278)' id='flowchart-RDC-11' class='node default'%3e%3crect height='54' width='209.421875' y='-27' x='-104.7109375' style='' class='basic label-container'/%3e%3cg transform='translate(-74.7109375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='149.421875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3erow data for tenant C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
다음으로, 이 멀티 테넌트 아키텍처를 구현하는 방법을 소개하겠습니다.
PostgreSQL 을 사용한 멀티 테넌트 아키텍처 구현 방법
모든 리소스에 테넌트 식별자 추가
CRM 시스템에서는 많은 리소스가 있으며, 이들은 다양한 테이블에 저장됩니다. 예를 들어, 고객 정보는 customers 테이블에 저장됩니다.
멀티 테넌시를 구현하기 전, 이러한 리소스들은 특정 테넌트와 연관되지 않았습니다:
%3bopacity:0.7%3bbackground-color:hsl(80%2c 100%25%2c 96.2745098039%25)%3b%7d%23mermaid-1 .relationshipLabelBox rect%7bopacity:0.5%3b%7d%23mermaid-1 .relationshipLine%7bstroke:%23333333%3b%7d%23mermaid-1 .entityTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-1 %23MD_PARENT_START%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-1 %23MD_PARENT_END%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='240' markerWidth='190' refY='7' refX='0' id='MD_PARENT_START'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='19' id='MD_PARENT_END'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='0' id='ONLY_ONE_START'%3e%3cpath d='M9%2c0 L9%2c18 M15%2c0 L15%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='18' id='ONLY_ONE_END'%3e%3cpath d='M3%2c0 L3%2c18 M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='0' id='ZERO_OR_ONE_START'%3e%3ccircle r='6' cy='9' cx='21' fill='white' stroke='gray'/%3e%3cpath d='M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='30' id='ZERO_OR_ONE_END'%3e%3ccircle r='6' cy='9' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c0 L21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='18' id='ONE_OR_MORE_START'%3e%3cpath d='M0%2c18 Q 18%2c0 36%2c18 Q 18%2c36 0%2c18 M42%2c9 L42%2c27' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='27' id='ONE_OR_MORE_END'%3e%3cpath d='M3%2c9 L3%2c27 M9%2c18 Q27%2c0 45%2c18 Q27%2c36 9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='18' id='ZERO_OR_MORE_START'%3e%3ccircle r='6' cy='18' cx='48' fill='white' stroke='gray'/%3e%3cpath d='M0%2c18 Q18%2c0 36%2c18 Q18%2c36 0%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='39' id='ZERO_OR_MORE_END'%3e%3ccircle r='6' cy='18' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c18 Q39%2c0 57%2c18 Q39%2c36 21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cg transform='translate(20%2c20 )' id='entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530'%3e%3crect height='66' width='100' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(50%2c12)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530' class='er entityLabel'%3ecustomers%3c/text%3e%3crect height='21' width='49.71397399902344' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='50.28602600097656' y='24' x='49.71397399902344' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(54.71397399902344%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='49.71397399902344' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='50.28602600097656' y='45' x='49.71397399902344' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(54.71397399902344%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-name' class='er entityLabel'%3ename%3c/text%3e%3c/g%3e%3c/svg%3e)
다른 리소스를 소유한 테넌트를 구분하기 위해 테넌트 테이블을 도입하여 테넌트 정보를 저장하고(db_user 및 db_user_password는 각 테넌트의 데이터베이스 연결 정보를 저장하는 데 사용되며, 이는 아래에 자세히 설명됩니다), 각 리소스에 tenant_id 필드를 추가하여 어느 테넌트에 속하는지를 식별합니다:
%3bopacity:0.7%3bbackground-color:hsl(80%2c 100%25%2c 96.2745098039%25)%3b%7d%23mermaid-2 .relationshipLabelBox rect%7bopacity:0.5%3b%7d%23mermaid-2 .relationshipLine%7bstroke:%23333333%3b%7d%23mermaid-2 .entityTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-2 %23MD_PARENT_START%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-2 %23MD_PARENT_END%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='240' markerWidth='190' refY='7' refX='0' id='MD_PARENT_START'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='19' id='MD_PARENT_END'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='0' id='ONLY_ONE_START'%3e%3cpath d='M9%2c0 L9%2c18 M15%2c0 L15%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='18' id='ONLY_ONE_END'%3e%3cpath d='M3%2c0 L3%2c18 M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='0' id='ZERO_OR_ONE_START'%3e%3ccircle r='6' cy='9' cx='21' fill='white' stroke='gray'/%3e%3cpath d='M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='30' id='ZERO_OR_ONE_END'%3e%3ccircle r='6' cy='9' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c0 L21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='18' id='ONE_OR_MORE_START'%3e%3cpath d='M0%2c18 Q 18%2c0 36%2c18 Q 18%2c36 0%2c18 M42%2c9 L42%2c27' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='27' id='ONE_OR_MORE_END'%3e%3cpath d='M3%2c9 L3%2c27 M9%2c18 Q27%2c0 45%2c18 Q27%2c36 9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='18' id='ZERO_OR_MORE_START'%3e%3ccircle r='6' cy='18' cx='48' fill='white' stroke='gray'/%3e%3cpath d='M0%2c18 Q18%2c0 36%2c18 Q18%2c36 0%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='39' id='ZERO_OR_MORE_END'%3e%3ccircle r='6' cy='18' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c18 Q39%2c0 57%2c18 Q39%2c36 21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cg transform='translate(20%2c20 )' id='entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e'%3e%3crect height='87' width='131.66140747070312' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(65.83070373535156%2c12)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e' class='er entityLabel'%3etenants%3c/text%3e%3crect height='21' width='35.245819091796875' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='24' x='35.245819091796875' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c34.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='35.245819091796875' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='45' x='35.245819091796875' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c55.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-2-name' class='er entityLabel'%3edb_user%3c/text%3e%3crect height='21' width='35.245819091796875' y='66' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c76.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-3-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='66' x='35.245819091796875' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c76.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-3-name' class='er entityLabel'%3edb_user_password%3c/text%3e%3c/g%3e%3cg transform='translate(251.66140747070312%2c20 )' id='entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530'%3e%3crect height='87' width='100' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(50%2c12)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530' class='er entityLabel'%3ecustomers%3c/text%3e%3crect height='21' width='41.49632263183594' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='24' x='41.49632263183594' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='41.49632263183594' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='45' x='41.49632263183594' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-name' class='er entityLabel'%3ename%3c/text%3e%3crect height='21' width='41.49632263183594' y='66' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c76.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-3-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='66' x='41.49632263183594' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c76.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-3-name' class='er entityLabel'%3etenant_id%3c/text%3e%3c/g%3e%3c/svg%3e)
이제 각 리소스는 tenant_id와 연관되어 있으며, 이론적으로 모든 쿼리에 where 절을 추가하여 각 테넌트에 대한 리소스 접근을 제한할 수 있습니다:
처음에는 이 방법이 단순하고 실행 가능해 보입니다. 그러나 다음과 같은 문제들이 발생할 것입니다:
- 거의 모든 쿼리에서 이
where절을 포함해야 하며, 이는 코드가 복잡해지고 유지보수가 어렵게 만듭니다. 특히 복잡한 조인 문을 작성할 때 더욱 그렇습니다. - 코드베이스에 새로 합류한 사람들은 이
where절을 쉽게 추가하는 것을 잊어버릴 수 있습니다. - 다양한 테넌트 간 데이터가 진정으로 격리되지 않습니다. 각 테넌트는 여전히 다른 테넌트의 데이터에 접근할 수 있는 권한을 가지고 있습니다.
따라서 이 방법을 채택하지 않을 것입니다. 대신, PostgreSQL 의 행 수준 보안을 사용하여 이러한 문제를 해결할 것입니다. 그러나 진행하기 전에, 이 공유 데이터베이스에 접근하기 위해 각 테넌트를 위한 별도의 데이터베이스 계정을 생성할 것입니다.
테넌트를 위한 DB 역할 설정
데이터베이스에 연결할 수 있는 각 사용자에게 데이터베이스 역할을 할당하는 것은 좋은 관행입니다. 이를 통해 각 사용자의 데이터베이스 접근을 더 잘 제어할 수 있으며, 다른 사용자 간의 작업 격리를 용이하게 하고 시스템 안정성과 보안을 향상시킬 수 있습니다.
모든 테넌트가 동일한 데이터베이스 작업 권한을 가지고 있으므로, 이러한 권한을 관리할 기본 역할을 생성할 수 있습니다:
그런 다음 각 테넌트 역할을 구별하기 위해, 생성 시 기본 역할에서 상속된 역할을 각 테넌트에게 할당합니다:
다음으로, 각 테넌트의 데이터베이스 연결 정보는 테넌트 테이블에 저장됩니다:
| id | db_user | db_user_password |
|---|---|---|
| x2euic | crm_tenant_x2euic | pa55w0rd |
이 메커니즘은 각 테넌트에 고유한 데이터베이스 역할을 제공하며, 이러한 역할은 crm_tenant 역할에 부여된 권한을 공유합니다.
그런 다음, crm_tenant 역할을 사용하여 테넌트에 대한 권한 범위를 정의할 수 있습니다:
- 테넌트는 모든 CRM 시스템 리소스 테이블에 대한 CRUD 접근을 가져야 합니다.
- CRM 시스템 리소스와 관련이 없는 테이블은 테넌트에게 보이지 않아야 합니다(예를 들어
시스템테이블만 있다고 가정합니다). - 테넌트는
테넌트테이블을 수정할 수 없어야 하며, 오직id및db_user필드만 그들에게 보여야 합니다.
테넌트를 위한 역할이 설정되면, 테넌트가 서비스에 접근을 요청할 때, 해당 테넌트를 나타내는 데이터베이스 역할을 사용하여 데이터베이스와 상호작용할 수 있습니다:
%3bfill:%23ECECFF%3b%7d%23mermaid-3 text.actor%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .actor-line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-3 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-3 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-3 %23arrowhead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-3 .sequenceNumber%7bfill:white%3b%7d%23mermaid-3 %23sequencenumber%7bfill:%23333%3b%7d%23mermaid-3 %23crosshead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-3 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-3 .labelBox%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-3 .labelText%2c%23mermaid-3 .labelText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .loopText%2c%23mermaid-3 .loopText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-3 .note%7bstroke:%23aaaa33%3bfill:%23fff5ad%3b%7d%23mermaid-3 .noteText%2c%23mermaid-3 .noteText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-3 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23ECECFF%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-3 .actor-man line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-3 .actor-man circle%2c%23mermaid-3 line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3bstroke-width:2px%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol height='24' width='24' id='computer'%3e%3cpath d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol clip-rule='evenodd' fill-rule='evenodd' id='database'%3e%3cpath d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol height='24' width='24' id='clock'%3e%3cpath d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto-start-reverse' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='7.9' id='arrowhead'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker refY='4.5' refX='4' orient='auto' markerHeight='8' markerWidth='15' id='crosshead'%3e%3cpath style='stroke-dasharray: 0%2c 0%3b' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' stroke-width='1pt' stroke='black' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='15.5' id='filled-head'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='40' markerWidth='60' refY='15' refX='15' id='sequencenumber'%3e%3ccircle r='6' cy='15' cx='15'/%3e%3c/marker%3e%3c/defs%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='80' x='279'%3e%ed%85%8c%eb%84%8c%ed%8a%b8 A %ec%9d%98 %60tenant_id_a%60 %eb%a1%9c %eb%a6%ac%ec%86%8c%ec%8a%a4%eb%a5%bc %ec%9a%94%ec%b2%ad%ed%95%a9%eb%8b%88%eb%8b%a4.%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='111' x2='482' y1='111' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='126' x='758'%3e%eb%8d%b0%ec%9d%b4%ed%84%b0%eb%b2%a0%ec%9d%b4%ec%8a%a4 %ec%9e%90%ea%b2%a9 %ec%a6%9d%eb%aa%85 %ec%a1%b0%ed%9a%8c by %60tenant_id_a%60%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='157' x2='1029' y1='157' x1='487'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='172' x='761'%3e%ed%85%8c%eb%84%8c%ed%8a%b8 A %eb%a5%bc %ec%9c%84%ed%95%9c %eb%8d%b0%ec%9d%b4%ed%84%b0%eb%b2%a0%ec%9d%b4%ec%8a%a4 %ec%9e%90%ea%b2%a9 %ec%a6%9d%eb%aa%85%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='201' x2='490' y1='201' x1='1032'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='216' x='758'%3e%ed%85%8c%eb%84%8c%ed%8a%b8 A %ec%9d%98 %eb%8d%b0%ec%9d%b4%ed%84%b0%eb%b2%a0%ec%9d%b4%ec%8a%a4 %ec%9e%90%ea%b2%a9 %ec%a6%9d%eb%aa%85%ec%9d%84 %ec%82%ac%ec%9a%a9%ed%95%98%ec%97%ac %eb%8d%b0%ec%9d%b4%ed%84%b0%eb%b2%a0%ec%9d%b4%ec%8a%a4 %ec%97%b0%ea%b2%b0 %ec%84%a4%ec%a0%95%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='245' x2='1029' y1='245' x1='487'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='260' x='761'%3e%ed%85%8c%eb%84%8c%ed%8a%b8 A %eb%a5%bc %ec%9c%84%ed%95%9c %eb%8d%b0%ec%9d%b4%ed%84%b0%eb%b2%a0%ec%9d%b4%ec%8a%a4 %ec%97%b0%ea%b2%b0%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='289' x2='490' y1='289' x1='1032'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='304' x='758'%3e%ed%85%8c%eb%84%8c%ed%8a%b8 A %ec%9d%98 %eb%a6%ac%ec%86%8c%ec%8a%a4%eb%a5%bc %ed%85%8c%eb%84%8c%ed%8a%b8 A %eb%8d%b0%ec%9d%b4%ed%84%b0%eb%b2%a0%ec%9d%b4%ec%8a%a4 %ec%97%b0%ea%b2%b0%ec%9d%84 %ed%86%b5%ed%95%b4 %ea%b0%80%ec%a0%b8%ec%98%b5%eb%8b%88%eb%8b%a4.%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='333' x2='1029' y1='333' x1='487'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='348' x='761'%3e%ed%85%8c%eb%84%8c%ed%8a%b8 A %ec%9d%98 %eb%a6%ac%ec%86%8c%ec%8a%a4%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='377' x2='490' y1='377' x1='1032'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='392' x='282'%3e%ed%85%8c%eb%84%8c%ed%8a%b8 A %ec%9d%98 %eb%a6%ac%ec%86%8c%ec%8a%a4%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='421' x2='79' y1='421' x1='485'/%3e%3c/svg%3e)
PostgreSQL 행 수준 보안을 사용하여 테넌트 데이터를 보호하기
지금까지 우리는 테넌트에 대한 대응하는 데이터베이스 역할을 설정했지만, 이는 테넌트 간 데이터 접근을 제한하지 않습니다. 다음으로, PostgreSQL 의 행 수준 보안 기능을 활용하여 각 테넌트가 자신의 데이터에만 접근하도록 제한할 것입니다.
PostgreSQL 에서는 테이블이 행 보안 정책 을 가지고 있어서 쿼리가 접근 가능하거나 데이터 조작 명령이 수정할 수 있는 행을 제한할 수 있습니다. 이 기능은 또한 RLS (행 수준 보안) 라고 알려져 있습니다.
기본적으로 테이블은 행 보안 정책을 가지고 있지 않습니다. RLS 를 활용하려면, 해당 테이블에 대한 RLS 를 활성화하고 테이블에 접근할 때마다 실행될 수 있는 보안 정책을 생성해야 합니다.
CRM 시스템의 고객 테이블을 예로 들어, RLS 를 활성화하고 각 테넌트가 자신들의 고객 데이터에만 접근할 수 있도록 하는 보안 정책을 생성해 보겠습니다:
보안 정책 생성 구문에서:
for all(옵션) 은 이 접근 정책이 테이블에 대한select,insert,update, 그리고delete작업에 대해 사용될 것임을 나타냅니다. 특정 작업에 대한 접근 정책을 지정하려면for뒤에 명령어 키워드를 추가합니다.to crm_tenant는 이 정책이 데이터베이스 역할crm_tenant를 가진 사용자에게 적용됨을 나타내며, 이는 모든 테넌트를 의미합니다.as restrictive는 정책의 강제 모드를 지정하며, 접근을 엄격히 제한해야 함을 나타냅니다. 기본적으로 테이블은 여러 정책을 가질 수 있으며, 여러허용정책은OR관계로 결합됩니다. 이 시나리오에서는 CRM 시스템 테넌트를 위한 사용자에게 이 정책 검사를 반드시 실행하도록 만들고 싶기 때문에 이 정책을제한적으로 선언합니다.using표현식은 실제 접근을 위한 조건을 정의하며, 현재 쿼리하는 데이터베이스 사용자가 상응하는 테넌트의 데이터만 볼 수 있도록 제한합니다. 이 제약은 명령어(select,update, 또는delete)로 선택된 행에 적용됩니다.with check표현식은 데이터 행을 수정할 때(insert또는update) 필요한 제약을 정의하며, 테넌트가 자신들의 기록만 추가하거나 업데이트할 수 있도록 보장합니다.
RLS 를 사용하여 리소스 테이블에 대한 테넌트 접근을 제한하는 것은 여러 이점이 있습니다:
- 이 정책은 모든 쿼리 작업(
select,update, 또는delete)에where tenant_id = (select id from tenants where db_user = current_user)를 효과적으로 추가합니다. 예를 들어,select * from customers를 실행할 때, 이는select * from customers where tenant_id = (select id from tenants where db_user = current_user)를 실행하는 것과 동일합니다. 이는 애플리케이션 코드에서where조건을 명시적으로 추가할 필요성을 제거하여 단순화시키고 오류 발생 가능성을 줄입니�다. - 데이터 접근 권한을 데이터베이스 수준에서 중앙 집중적으로 제어하여 애플리케이션에서의 취약점이나 불일치를 완화하며, 시스템 보안을 향상시킵니다.
그러나 몇 가지 유의할 점이 있습니다:
- RLS 정책은 데이터의 각 행에 대해 실행됩니다. RLS 정책 내 쿼리 조건이 너무 복잡하면 시스템 성능에 큰 영향을 미칠 수 있습니다. 다행히도, 우리의 테넌트 데이터 확인 쿼리는 충분히 간단하여 성능에 영향을 미치지 않습니다. 이후 RLS 를 사용하여 다른 기능을 구현할 계획이 있다면 Supabase 의 행 수준 보안 성능 권장 사항을 따르며 RLS 성능을 최적화할 수 있습니다.
- RLS 정책은
insert작업이 일어날 때 자동으로tenant_id를 채우지 않습니다. 이는 테넌트가 자신들의 데이터를 삽입할 때만 제한하며, 데이터 삽입 시 여전히 테넌트 ID 를 제공해야 합니다. 이는 쿼리 과정과 일치하지 않으며, 개발 중 혼란을 초래하여 오류 발생 가능성을 증가시킬 수 있습니다(이는 이후 단계에서 해결할 것입니다).
customers 테이블 외에도, 모든 CRM 시스템 리소스 테이블에 동일한 작업을 적용해야 합니다(이 과정은 약간 번거롭겠지만, 테이블 초기화 시 이를 설정하는 프로그램을 작성할 수 있습니다), 따라서 다양한 테넌트 간 데이터를 격리합니다.
데이터 삽입을 위한 트리거 함수 생성
앞에서 언급한 것처럼, RLS(행 수준 보안)는 쿼리를 수행할 때 tenant_id 의 존재에 대해 걱정할 필요가 없게 합니다. 데이터베이스가 자동으로 처리하기 때문입니다. 하지만 insert 작업의 경우 여전히 적절한 tenant_id 를 수동으로 지정해야 합니다.
데이터 삽입 시 RLS 와 유사한 편리함을 얻기 위해, 데이터 삽입 시 데이터베이스가 tenant_id 를 자동으로 처리할 수 있어야 합니다.
이러한 편리함은 명확한 이점을 제공합니다: 애플리케이션 개발 레벨에서 데이터가 속한 테넌트를 더 이상 고려할 필요가 없으며, 오류 발생 가능성을 줄이고 멀티 테넌트 애플리케이션 개발 상황에서 우리가 감내해야 하는 정신적 부담을 덜어줍니다.
다행히도 PostgreSQL 는 강력한 트리거 기능을 제공합니다.
트리거는 테이블과 관련된 특별한 함수로, 특정 작업(예: insert, update, 또는 delete)이 수행될 때 자동으로 특정 작업을 수행합니다. 이들 작업은 행 수준(각 행) 또는 문 수준(전체 문)에서 실행될 수 있습니다. 트리거를 사용하면 특정 데이터베이스 작업 전후에 사용자 정의 로직을 실행할 수 있으며, 이를 통해 우리의 목표를 쉽게 달성할 수 있습니다.
먼저, 각 데이터 삽입 전에 실행될 트리거 함수 set_tenant_id 를 생성합니다:
다음으로, 이 트리거 함수를 customers 테이블의 삽입 작업과 연결합니다(마치 테이블에 대해 RLS 를 활성화하듯이, 이 트리거 함수는 모든 관련 테이블과 연결되어야 합니다):
이 트리거는 삽입된 데이터가 올바른 tenant_id 를 포함하도록 보장합니다. 새로운 데이터에 이미 tenant_id 가 포함되어 있다면, 트리거 함수는 아무 작업도 하지 않습니다. 그렇지 않으면, tenants 테이블의 현재 사용자 정보를 기준으로 tenant_id 필드를 자동으로 채웁니다.
이렇게 하면 테넌트가 데이터 삽입 시 데이터베이스 레벨에서 tenant_id 를 자동으로 처리하는 것을 달성합니다.
요약
이 기사에서는 CRM 시스템을 예로 들어 PostgreSQL 데이터베이스를 활용한 실용적인 �멀티 테넌트 아키텍처 구현을 탐구했습니다.
데이터베이스 역할 관리, 접근 제어, 그리고 PostgreSQL의 행 수준 보안 기능 등을 논의하여 테넌트 간의 데이터 격리를 보장했습니다. 또한 트리거 함수를 사용하여 여러 테넌트를 관리하는데 개발자들의 인지적 부담을 줄였습니다.
이 기사에서 다룬 내용은 여기까지 입니다. 사용자 접근 관리를 통해 멀티 테넌트 애플리케이션을 더욱 강력하게 만들고 싶다면, Logto 조직으로 멀티 테넌트 앱 뻑뻑하게 가이드 - Logto로 시작하기를 참조할 수 있습니다.