Implementación de multiarquitectura con PostgreSQL: Aprende a través de un simple ejemplo del mundo real
Aprende cómo implementar arquitectura multiusuario con Seguridad a Nivel de Fila (RLS) de PostgreSQL y roles de base de datos a través de un ejemplo del mundo real para el aislamiento seguro de datos entre usuarios.

Developer

En algunos de nuestros artículos anteriores, profundizamos en el concepto de multiarquitectura y sus aplicaciones en productos y escenarios de negocios del mundo real.
En este artículo, exploraremos cómo implementar una arquitectura multiusuario para tu aplicación usando PostgreSQL desde una perspectiva técnica.
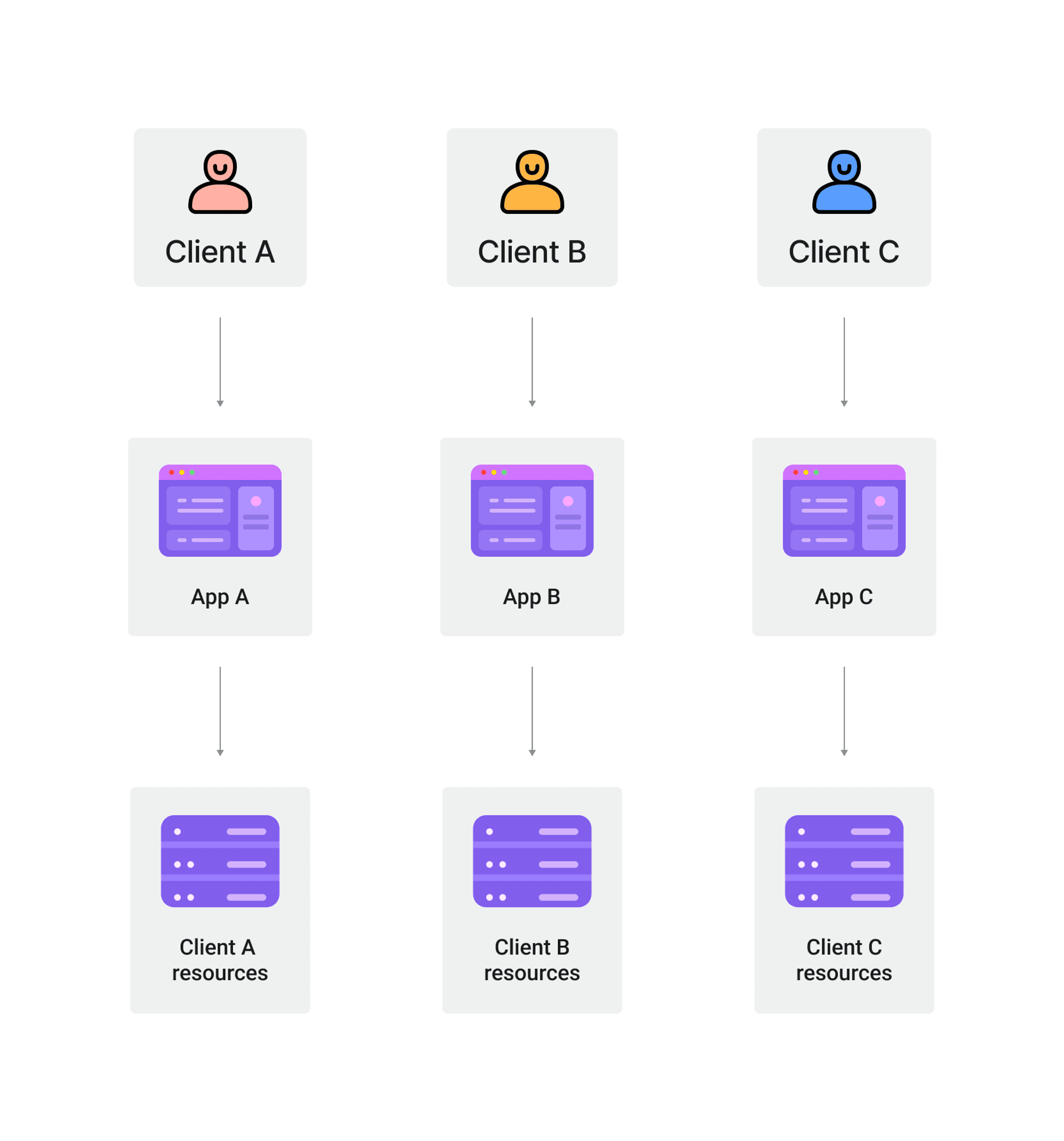
¿Qué es la arquitectura de un solo usuario?
La arquitectura de un solo usuario se refiere a una arquitectura de software donde cada cliente tiene su propia instancia dedicada de la aplicación y la base de datos.
En esta arquitectura, los datos y recursos de cada usuario están completamente aislados de otros usuarios.
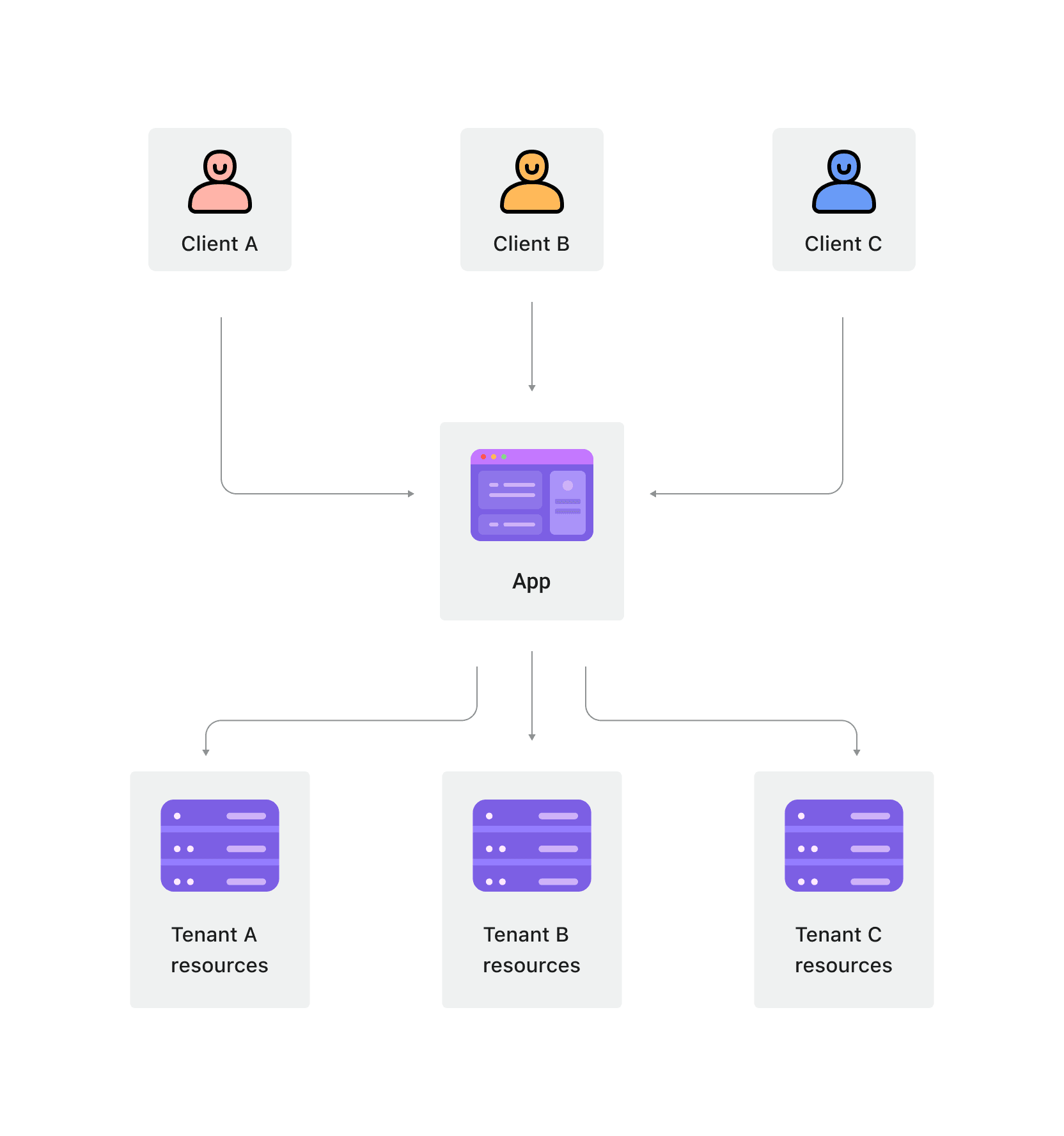
¿Qué es la arquitectura multiusuario?
La arquitectura multiusuario es una arquitectura de software donde múltiples clientes (usuarios) comparten la misma instancia de aplicación e infraestructura manteniendo el aislamiento de datos. En esta arquitectura, una sola instancia del software atiende a múltiples usuarios, manteniendo los datos de cada usuario separados de otros mediante varios mecanismos de aislamiento.
Arquitectura de un solo usuario vs arquitectura multiusuario
La arquitectura de un solo usuario y la arquitectura multiusuario difieren en aspectos tales como el aislamiento de datos, utilización de recursos, escalabilidad, gestión y mantenimiento, y seguridad.
En la arquitectura de un solo usuario, cada cliente tiene un espacio de datos independiente, lo que conduce a una menor utilización de recursos pero relativamente más simple para la personalización. Típicamente, el software de un solo usuario se adapta a las necesidades específicas del cliente, como sistemas de inventario para un proveedor de tela en particular o una aplicación web de blog personal. La característica común entre ellos es que cada cliente ocupa una instancia separada del servicio de la aplicación, lo que facilita la personalización para cumplir con los requisitos específicos.
En una arquitectura multiusuario, múltiples usuarios comparten los mismos recursos subyacentes, resultando en una mayor utilización de recursos. Sin embargo, es crucial asegurar el aislamiento de datos y la seguridad.
La arquitectura multiusuario es a menudo la arquitectura de software preferida cuando los proveedores de servicios ofrecen servicios estandarizados a diferentes clientes. Estos servicios generalmente tienen bajos niveles de personalización, y todos los clientes comparten la misma instancia de aplicación. Cuando una aplicación requiere una actualización, actualizar una instancia de aplicación equivale a actualizar la aplicación para todos los clientes. Por ejemplo, CRM (Gestión de Relación con Clientes) es un requerimiento estandarizado. Estos sistemas suelen usar una arquitectura multiusuario para proporcionar el mismo servicio a todos los usuarios.
Estrategias de aislamiento de datos de usuarios en arquitectura multiusuario
En una arquitectura multiusuario, todos los usuarios comparten los mismos recursos subyacentes, haciendo que el aislamiento de recursos entre usuarios sea crucial. Este aislamiento no necesariamente necesita ser físico; simplemente requiere garantizar que los recursos de un usuario no sean visibles para otros.
En el diseño de la arquitectura, se pueden lograr varios grados de aislamiento de recursos entre usuarios:

En general, cuántos más recursos se compartan entre usuarios, menor será el costo de iteración y mantenimiento del sistema. A la inversa, cuantos menos recursos se compartan, mayor será el costo.
Comenzando la implementación multiusuario con un ejemplo del mundo real
En este artículo, utilizaremos un sistema CRM como ejemplo para introducir una arquitectura multiusuario simple pero práctica.
Reconocemos que todos los usuarios utilizan los mismos servicios estándar, por lo que decidimos que todos los usuarios compartan los mismos recursos básicos, e implementaremos el aislamiento de datos entre diferentes usuarios a nivel de base de datos usando la Seguridad a Nivel de Fila de PostgreSQL.
Además, crearemos una conexión de datos separada para cada usuario para facilitar una mejor gestión de permisos de los usuarios.
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape rect%2c%23mermaid-0 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg data-look='classic' id='Database' class='cluster'%3e%3crect height='332' width='259.421875' y='8' x='732.46875' style=''/%3e%3cg transform='translate(827.9296875%2c 8)' class='cluster-label'%3e%3cforeignObject height='24' width='68.5'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eDatabase%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg data-look='classic' id='subGraph0' class='cluster'%3e%3crect height='332' width='230.078125' y='8' x='260.28125' style=''/%3e%3cg transform='translate(328.203125%2c 8)' class='cluster-label'%3e%3cforeignObject height='24' width='94.234375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eCRM System%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_A_TA_0' d='M209.398%2c70L213.712%2c70C218.026%2c70%2c226.654%2c70%2c235.134%2c70C243.615%2c70%2c251.948%2c70%2c259.836%2c70C267.724%2c70%2c275.167%2c70%2c278.888%2c70L282.609%2c70'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_B_TB_1' d='M209.844%2c174L214.083%2c174C218.323%2c174%2c226.802%2c174%2c235.208%2c174C243.615%2c174%2c251.948%2c174%2c259.689%2c174C267.43%2c174%2c274.578%2c174%2c278.152%2c174L281.727%2c174'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_C_TC_2' d='M210.281%2c278L214.448%2c278C218.615%2c278%2c226.948%2c278%2c235.281%2c278C243.615%2c278%2c251.948%2c278%2c259.615%2c278C267.281%2c278%2c274.281%2c278%2c277.781%2c278L281.281%2c278'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TA_RDA_3' d='M464.031%2c70L468.419%2c70C472.807%2c70%2c481.583%2c70%2c506.147%2c70C530.711%2c70%2c571.063%2c70%2c611.414%2c70C651.766%2c70%2c692.117%2c70%2c715.94%2c70C739.763%2c70%2c747.057%2c70%2c750.704%2c70L754.352%2c70'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TB_RDB_4' d='M464.914%2c174L469.155%2c174C473.396%2c174%2c481.878%2c174%2c506.294%2c174C530.711%2c174%2c571.063%2c174%2c611.414%2c174C651.766%2c174%2c692.117%2c174%2c715.867%2c174C739.617%2c174%2c746.766%2c174%2c750.34%2c174L753.914%2c174'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TC_RDC_5' d='M465.359%2c278L469.526%2c278C473.693%2c278%2c482.026%2c278%2c506.368%2c278C530.711%2c278%2c571.063%2c278%2c611.414%2c278C651.766%2c278%2c692.117%2c278%2c715.793%2c278C739.469%2c278%2c746.469%2c278%2c749.969%2c278L753.469%2c278'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(611.4140625%2c 70)' class='edgeLabel'%3e%3cg transform='translate(-95.171875%2c -12)' class='label'%3e%3cforeignObject height='24' width='190.34375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB connection for tenant A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(611.4140625%2c 174)' class='edgeLabel'%3e%3cg transform='translate(-95.6171875%2c -12)' class='label'%3e%3cforeignObject height='24' width='191.234375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB connection for tenant B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(611.4140625%2c 278)' class='edgeLabel'%3e%3cg transform='translate(-96.0546875%2c -12)' class='label'%3e%3cforeignObject height='24' width='192.109375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB connection for tenant C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(375.3203125%2c 70)' id='flowchart-TA-0' class='node default'%3e%3crect height='54' width='177.421875' y='-27' x='-88.7109375' style='' class='basic label-container'/%3e%3cg transform='translate(-58.7109375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='117.421875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant A context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(375.3203125%2c 174)' id='flowchart-TB-1' class='node default'%3e%3crect height='54' width='179.1875' y='-27' x='-89.59375' style='' class='basic label-container'/%3e%3cg transform='translate(-59.59375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='119.1875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant B context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(375.3203125%2c 278)' id='flowchart-TC-2' class='node default'%3e%3crect height='54' width='180.078125' y='-27' x='-90.0390625' style='' class='basic label-container'/%3e%3cg transform='translate(-60.0390625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='120.078125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant C context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(109.140625%2c 70)' id='flowchart-A-3' class='node default'%3e%3crect height='54' width='200.515625' y='-27' x='-100.2578125' style='' class='basic label-container'/%3e%3cg transform='translate(-70.2578125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='140.515625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient from tenant A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(109.140625%2c 174)' id='flowchart-B-5' class='node default'%3e%3crect height='54' width='201.40625' y='-27' x='-100.703125' style='' class='basic label-container'/%3e%3cg transform='translate(-70.703125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='141.40625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient from tenant B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(109.140625%2c 278)' id='flowchart-C-7' class='node default'%3e%3crect height='54' width='202.28125' y='-27' x='-101.140625' style='' class='basic label-container'/%3e%3cg transform='translate(-71.140625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='142.28125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient from tenant C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(862.1796875%2c 70)' id='flowchart-RDA-9' class='node default'%3e%3crect height='54' width='207.65625' y='-27' x='-103.828125' style='' class='basic label-container'/%3e%3cg transform='translate(-73.828125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='147.65625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3erow data for tenant A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(862.1796875%2c 174)' id='flowchart-RDB-10' class='node default'%3e%3crect height='54' width='208.53125' y='-27' x='-104.265625' style='' class='basic label-container'/%3e%3cg transform='translate(-74.265625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='148.53125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3erow data for tenant B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(862.1796875%2c 278)' id='flowchart-RDC-11' class='node default'%3e%3crect height='54' width='209.421875' y='-27' x='-104.7109375' style='' class='basic label-container'/%3e%3cg transform='translate(-74.7109375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='149.421875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3erow data for tenant C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
A continuación, introduciremos cómo implementar esta arquitectura multiusuario.
Cómo implementar la arquitectura multiusuario con PostgreSQL
Añadir identificador de usuario para todos los recursos
En un sistema CRM, tendremos muchos recursos y estos se almacenan en diferentes tablas. Por ejemplo, la información del cliente se almacena en la tabla customers.
Antes de implementar la multiarquitectura, estos recursos no están asociados con ningún usuario:
%3bopacity:0.7%3bbackground-color:hsl(80%2c 100%25%2c 96.2745098039%25)%3b%7d%23mermaid-1 .relationshipLabelBox rect%7bopacity:0.5%3b%7d%23mermaid-1 .relationshipLine%7bstroke:%23333333%3b%7d%23mermaid-1 .entityTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-1 %23MD_PARENT_START%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-1 %23MD_PARENT_END%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='240' markerWidth='190' refY='7' refX='0' id='MD_PARENT_START'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='19' id='MD_PARENT_END'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='0' id='ONLY_ONE_START'%3e%3cpath d='M9%2c0 L9%2c18 M15%2c0 L15%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='18' id='ONLY_ONE_END'%3e%3cpath d='M3%2c0 L3%2c18 M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='0' id='ZERO_OR_ONE_START'%3e%3ccircle r='6' cy='9' cx='21' fill='white' stroke='gray'/%3e%3cpath d='M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='30' id='ZERO_OR_ONE_END'%3e%3ccircle r='6' cy='9' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c0 L21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='18' id='ONE_OR_MORE_START'%3e%3cpath d='M0%2c18 Q 18%2c0 36%2c18 Q 18%2c36 0%2c18 M42%2c9 L42%2c27' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='27' id='ONE_OR_MORE_END'%3e%3cpath d='M3%2c9 L3%2c27 M9%2c18 Q27%2c0 45%2c18 Q27%2c36 9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='18' id='ZERO_OR_MORE_START'%3e%3ccircle r='6' cy='18' cx='48' fill='white' stroke='gray'/%3e%3cpath d='M0%2c18 Q18%2c0 36%2c18 Q18%2c36 0%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='39' id='ZERO_OR_MORE_END'%3e%3ccircle r='6' cy='18' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c18 Q39%2c0 57%2c18 Q39%2c36 21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cg transform='translate(20%2c20 )' id='entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530'%3e%3crect height='66' width='100' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(50%2c12)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530' class='er entityLabel'%3ecustomers%3c/text%3e%3crect height='21' width='49.71397399902344' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='50.28602600097656' y='24' x='49.71397399902344' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(54.71397399902344%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='49.71397399902344' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='50.28602600097656' y='45' x='49.71397399902344' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(54.71397399902344%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-name' class='er entityLabel'%3ename%3c/text%3e%3c/g%3e%3c/svg%3e)
Para diferenciar los usuarios que poseen diferentes recursos, introducimos una tabla tenants para almacenar información de usuario (donde db_user y db_user_password se utilizan para almacenar la información de conexión a base de datos para cada usuario, serán detallados a continuación). Además, añadimos un campo tenant_id a cada recurso para identificar a qué usuario pertenece:
%3bopacity:0.7%3bbackground-color:hsl(80%2c 100%25%2c 96.2745098039%25)%3b%7d%23mermaid-2 .relationshipLabelBox rect%7bopacity:0.5%3b%7d%23mermaid-2 .relationshipLine%7bstroke:%23333333%3b%7d%23mermaid-2 .entityTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-2 %23MD_PARENT_START%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-2 %23MD_PARENT_END%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='240' markerWidth='190' refY='7' refX='0' id='MD_PARENT_START'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='19' id='MD_PARENT_END'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='0' id='ONLY_ONE_START'%3e%3cpath d='M9%2c0 L9%2c18 M15%2c0 L15%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='18' id='ONLY_ONE_END'%3e%3cpath d='M3%2c0 L3%2c18 M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='0' id='ZERO_OR_ONE_START'%3e%3ccircle r='6' cy='9' cx='21' fill='white' stroke='gray'/%3e%3cpath d='M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='30' id='ZERO_OR_ONE_END'%3e%3ccircle r='6' cy='9' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c0 L21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='18' id='ONE_OR_MORE_START'%3e%3cpath d='M0%2c18 Q 18%2c0 36%2c18 Q 18%2c36 0%2c18 M42%2c9 L42%2c27' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='27' id='ONE_OR_MORE_END'%3e%3cpath d='M3%2c9 L3%2c27 M9%2c18 Q27%2c0 45%2c18 Q27%2c36 9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='18' id='ZERO_OR_MORE_START'%3e%3ccircle r='6' cy='18' cx='48' fill='white' stroke='gray'/%3e%3cpath d='M0%2c18 Q18%2c0 36%2c18 Q18%2c36 0%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='39' id='ZERO_OR_MORE_END'%3e%3ccircle r='6' cy='18' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c18 Q39%2c0 57%2c18 Q39%2c36 21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cg transform='translate(20%2c20 )' id='entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e'%3e%3crect height='87' width='131.66140747070312' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(65.83070373535156%2c12)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e' class='er entityLabel'%3etenants%3c/text%3e%3crect height='21' width='35.245819091796875' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='24' x='35.245819091796875' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c34.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='35.245819091796875' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='45' x='35.245819091796875' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c55.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-2-name' class='er entityLabel'%3edb_user%3c/text%3e%3crect height='21' width='35.245819091796875' y='66' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c76.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-3-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='66' x='35.245819091796875' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c76.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-3-name' class='er entityLabel'%3edb_user_password%3c/text%3e%3c/g%3e%3cg transform='translate(251.66140747070312%2c20 )' id='entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530'%3e%3crect height='87' width='100' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(50%2c12)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530' class='er entityLabel'%3ecustomers%3c/text%3e%3crect height='21' width='41.49632263183594' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='24' x='41.49632263183594' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='41.49632263183594' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='45' x='41.49632263183594' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-name' class='er entityLabel'%3ename%3c/text%3e%3crect height='21' width='41.49632263183594' y='66' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c76.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-3-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='66' x='41.49632263183594' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c76.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-3-name' class='er entityLabel'%3etenant_id%3c/text%3e%3c/g%3e%3c/svg%3e)
Ahora, cada recurso está asociado con un tenant_id, lo que nos permite teóricamente añadir una cláusula where a todas las consultas para restringir el acceso a los recursos para cada usuario:
A primera vista, esto parece sencillo y factible. Sin embargo, tendrá los siguientes problemas:
- Casi todas las consultas incluirán esta cláusula
where, lo que desordenará el código y lo hará más difícil de mantener, especialmente al escribir declaraciones de unión complejas. - Los recién llegados al código pueden fácilmente olvidar añadir esta cláusula
where. - Los datos entre diferentes usuarios no están realmente aislados, ya que cada usuario aún tiene permisos para acceder a datos que pertenecen a otros usuarios.
Por lo tanto, no adoptaremos este enfoque. En su lugar, usaremos la Seguridad a Nivel de Fila de PostgreSQL para abordar estas inquietudes. Sin embargo, antes de proceder, crearemos una cuenta de base de datos dedicada para que cada usuario acceda a esta base de datos compartida.
Configurar roles de base de datos para usuarios
Es una buena práctica asignar un rol de base de datos a cada usuario que puede conectarse a la base de datos. Esto permite un mejor control del acceso de cada usuario a la base de datos, facilitando el aislamiento de operaciones entre diferentes usuarios y mejorando la estabilidad y seguridad del sistema.
Como todos los usuarios tienen los mismos permisos de operación de base de datos, podemos crear un rol base para gestionar estos permisos:
Luego, para diferenciar cada rol de usuario, se asigna un rol heredado del rol base a cada usuario al momento de la creación:
A continuación, la información de conexión de base de datos para cada usuario se almacenará en la tabla tenants:
| id | db_user | db_user_password |
|---|---|---|
| x2euic | crm_tenant_x2euic | pa55w0rd |
Este mecanismo proporciona a cada usuario su propio rol de base de datos, y estos roles comparten los permisos otorgados al rol crm_tenant.
Luego podemos definir el alcance de los permisos para los usuarios usando el rol crm_tenant:
- Los usuarios deben tener acceso CRUD a todas las tablas de recursos del sistema CRM.
- Las tablas no relacionadas con los recursos del sistema CRM deben ser invisibles para los usuarios (asumiendo solo la tabla
systems). - Los usuarios no deben poder modificar la tabla
tenants, y solo los camposidydb_userdeben ser visibles para ellos al consultar su propio id de usuario al realizar operaciones de base de datos.
Una vez configurados los roles para los usuarios, cuando un usuario solicite acceso al servicio, podemos interactuar con la base de datos utilizando el rol de base de datos que representa a ese usuario:
%3bfill:%23ECECFF%3b%7d%23mermaid-3 text.actor%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .actor-line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-3 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-3 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-3 %23arrowhead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-3 .sequenceNumber%7bfill:white%3b%7d%23mermaid-3 %23sequencenumber%7bfill:%23333%3b%7d%23mermaid-3 %23crosshead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-3 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-3 .labelBox%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-3 .labelText%2c%23mermaid-3 .labelText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .loopText%2c%23mermaid-3 .loopText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-3 .note%7bstroke:%23aaaa33%3bfill:%23fff5ad%3b%7d%23mermaid-3 .noteText%2c%23mermaid-3 .noteText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-3 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23ECECFF%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-3 .actor-man line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-3 .actor-man circle%2c%23mermaid-3 line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3bstroke-width:2px%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol height='24' width='24' id='computer'%3e%3cpath d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol clip-rule='evenodd' fill-rule='evenodd' id='database'%3e%3cpath d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol height='24' width='24' id='clock'%3e%3cpath d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto-start-reverse' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='7.9' id='arrowhead'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker refY='4.5' refX='4' orient='auto' markerHeight='8' markerWidth='15' id='crosshead'%3e%3cpath style='stroke-dasharray: 0%2c 0%3b' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' stroke-width='1pt' stroke='black' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='15.5' id='filled-head'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='40' markerWidth='60' refY='15' refX='15' id='sequencenumber'%3e%3ccircle r='6' cy='15' cx='15'/%3e%3c/marker%3e%3c/defs%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='80' x='283'%3eSolicitar recursos del usuario A con %60tenant_id_a%60%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='111' x2='489' y1='111' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='126' x='816'%3eRecuperar credenciales de DB de usuario por %60tenant_id_a%60%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='157' x2='1137' y1='157' x1='494'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='172' x='819'%3eCredenciales de DB para usuario A%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='201' x2='497' y1='201' x1='1140'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='216' x='816'%3eEstablecer conexi%c3%b3n DB para usuario A usando las credenciales DB del usuario A%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='245' x2='1137' y1='245' x1='494'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='260' x='819'%3eConexi%c3%b3n DB para usuario A%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='289' x2='497' y1='289' x1='1140'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='304' x='816'%3eRecuperar recursos de usuario A a trav%c3%a9s de la conexi%c3%b3n DB del usuario A%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='333' x2='1137' y1='333' x1='494'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='348' x='819'%3eRecursos del usuario A%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='377' x2='497' y1='377' x1='1140'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='392' x='286'%3eRecursos del usuario A%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='421' x2='79' y1='421' x1='492'/%3e%3c/svg%3e)
Asegurar los datos del usuario usando Seguridad a Nivel de Fila de PostgreSQL
Hasta ahora, hemos establecido roles de base de datos correspondientes para los usuarios, pero esto no restringe el acceso a datos entre usuarios. A continuación, utilizaremos la función de Seguridad a Nivel de Fila de PostgreSQL para limitar el acceso de cada usuario solo a sus propios datos.
En PostgreSQL, las tablas pueden tener políticas de seguridad de filas que controlan qué filas pueden ser accedidas por consultas o modificadas por comandos de manipulación de datos. Esta característica también se conoce como RLS (Seguridad a Nivel de Fila).
Por defecto, las tablas no tienen políticas de seguridad de filas. Para utilizar RLS, necesitas habilitarla para la tabla y crear políticas de seguridad que se ejecuten cada vez que la tabla sea accedida.
Tomando la tabla customers en el sistema CRM como ejemplo, habilitaremos RLS y crearemos una política de seguridad para restringir que cada usuario solo tenga acceso a los datos de sus propios clientes:
En la declaración que crea la política de seguridad:
for all(opcional) indica que esta política de acceso se utilizará para operacionesselect,insert,update, ydeleteen la tabla. Puedes especificar una política de acceso para operaciones específicas utilizandoforseguido de la palabra clave del comando.to crm_tenantindica que esta política se aplica a usuarios con el rol de base de datoscrm_tenant, es decir, todos los usuarios.as restrictiveespecifica el modo de aplicación de la política, indicando que el acceso debe estar estrictamente limitado. Por defecto, una tabla puede tener múltiples políticas, múltiples políticaspermissiveserán combinadas con una relaciónOR. En este escenario, declaramos esta política comorestrictiveporque deseamos que este chequeo de política sea obligatorio para los usuarios que pertenecen a usuarios del sistema CRM.- La expresión
usingdefine las condiciones para el acceso real, restringiendo al usuario de base de datos que realiza la consulta actualmente a solo ver datos que pertenecen a su respectivo usuario. Esta restricción se aplica a las filas seleccionadas por un comando (select,update, odelete). - La expresión
with checkdefine la restricción necesaria al modificar las filas de datos (insertoupdate), garantizando que los usuarios solo pueden añadir o actualizar registros para ellos mismos.
Usar RLS para restringir el acceso de usuarios a nuestras tablas de recursos ofrece varios beneficios:
- Esta política efectivamente añade
where tenant_id = (select id from tenants where db_user = current_user)a todas las operaciones de consulta (select,update, odelete). Por ejemplo, cuando ejecutasselect * from customers, es equivalente a ejecutarselect * from customers where tenant_id = (select id from tenants where db_user = current_user). Esto elimina la necesidad de añadir explícitamente condicioneswhereen el código de la aplicación, simplificándolo y reduciendo la probabilidad de errores. - Controla centralmente los permisos de acceso a datos entre diferentes usuarios a nivel de base de datos, mitigando el riesgo de vulnerabilidades o inconsistencias en la aplicación, mejorando así la seguridad del sistema.
Sin embargo, hay algunos puntos a considerar:
- Las políticas RLS se ejecutan para cada fila de datos. Si las condiciones de consulta dentro de la política RLS son demasiado complejas, podría impactar significativamente en el rendimiento del sistema. Afortunadamente, nuestra verificación de datos de usuario es lo suficientemente simple y no afectará el rendimiento. Si planeas implementar otras funcionalidades utilizando RLS más adelante, puedes seguir las recomendaciones de rendimiento de Seguridad a Nivel de Fila de Supabase para optimizar el rendimiento de RLS.
- Las políticas RLS no completan automáticamente
tenant_iddurante las operacionesinsert. Solo restringen a los usuarios a insertar sus propios datos. Esto significa que al insertar datos, todavía necesitamos proporcionar el ID de usuario, lo cual es inconsistente con el proceso de consulta y puede llevar a confusiones durante el desarrollo, aumentando la probabilidad de errores (esto se abordará en los pasos siguientes).
Además de la tabla customers, necesitamos aplicar las mismas operaciones a todas las tablas de recursos del sistema CRM (este proceso puede ser un poco tedioso, pero podemos escribir un programa para configurarlo durante la inicialización de las tablas), aislando así los datos de diferentes usuarios.
Crear función de disparador para inserción de datos
Como se mencionó anteriormente, RLS (Seguridad a Nivel de Fila) nos permite ejecutar consultas sin preocuparnos por la existencia de tenant_id, ya que la base de datos se encarga de ello automáticamente. Sin embargo, para operaciones insert, todavía necesitamos especificar manualmente el tenant_id correspondiente.
Para lograr una conveniencia similar a RLS para la inserción de datos, necesitamos que la base de datos pueda manejar tenant_id automáticamente durante la inserción de datos.
Esto tiene un beneficio claro: a nivel de desarrollo de aplicaciones, ya no necesitamos considerar a qué usuario pertenecen los datos, reduciendo la probabilidad de errores y facilitando nuestra carga mental cuando desarrollamos aplicaciones multiusuario.
Afortunadamente, PostgreSQL proporciona una potente funcionalidad de disparadores.
Los disparadores son funciones especiales asociadas con tablas que ejecutan automáticamente acciones específicas (como insert, update, o delete) cuando se realizan en la tabla. Estas acciones pueden ser activadas a nivel de fila (para cada fila) o a nivel de declaración (para toda la declaración). Con los disparadores, podemos ejecutar lógica personalizada antes o después de operaciones específicas de base de datos, permitiéndonos lograr fácilmente nuestro objetivo.
Primero, creemos una función de disparador set_tenant_id que se ejecutará antes de cada inserción de datos:
A continuación, asociamos esta función de disparador con la tabla customers para las operaciones de inserción (similar a habilitar RLS para una tabla, esta función de disparador necesita ser asociada con todas las tablas relevantes):
Este disparador asegura que los datos insertados contengan el tenant_id correcto. Si los nuevos datos ya incluyen un tenant_id, la función de disparador no hace nada. De lo contrario, llena automáticamente el campo tenant_id basado en la información del usuario actual en la tabla tenants.
De esta manera, logramos el manejo automático del tenant_id a nivel de base de datos durante la inserción de datos por los usuarios.
Resumen
En este artículo, profundizamos en la aplicación práctica de la arquitectura multiusuario, usando un sistema CRM como ejemplo para demostrar una solución práctica utilizando la base de datos PostgreSQL.
Discutimos la gestión de roles de base de datos, el control de acceso, y la característica de Seguridad a Nivel de Fila de PostgreSQL para asegurar el aislamiento de datos entre usuarios. Además, utilizamos funciones disparadoras para reducir la carga cognitiva de los desarrolladores en la gestión de diferentes usuarios.
Eso es todo por este artículo. Si deseas mejorar aún más tu aplicación multiusuario con la gestión de acceso de usuarios, puedes referirte a Una guía fácil para empezar con organizaciones Logto - para construir una aplicación multiusuario para más ideas.