Multi-Tenancy-Implementierung mit PostgreSQL: Lernen Sie durch ein einfaches Beispiel aus der Praxis
Erfahren Sie, wie Sie eine Multi-Tenant-Architektur mit PostgreSQL Row-Level Security (RLS) und Datenbankrollen anhand eines realen Beispiels implementieren, um eine sichere Datenisolation zwischen den Mietern zu gewährleisten.

Developer

In einigen unserer vorherigen Artikel haben wir uns mit dem Konzept der Multi-Tenancy und seinen Anwendungen in Produkten und realen Geschäftsszenarien beschäftigt.
In diesem Artikel werden wir erkunden, wie man aus technischer Sicht eine Multi-Tenant-Architektur für Ihre Anwendung mit PostgreSQL implementiert.
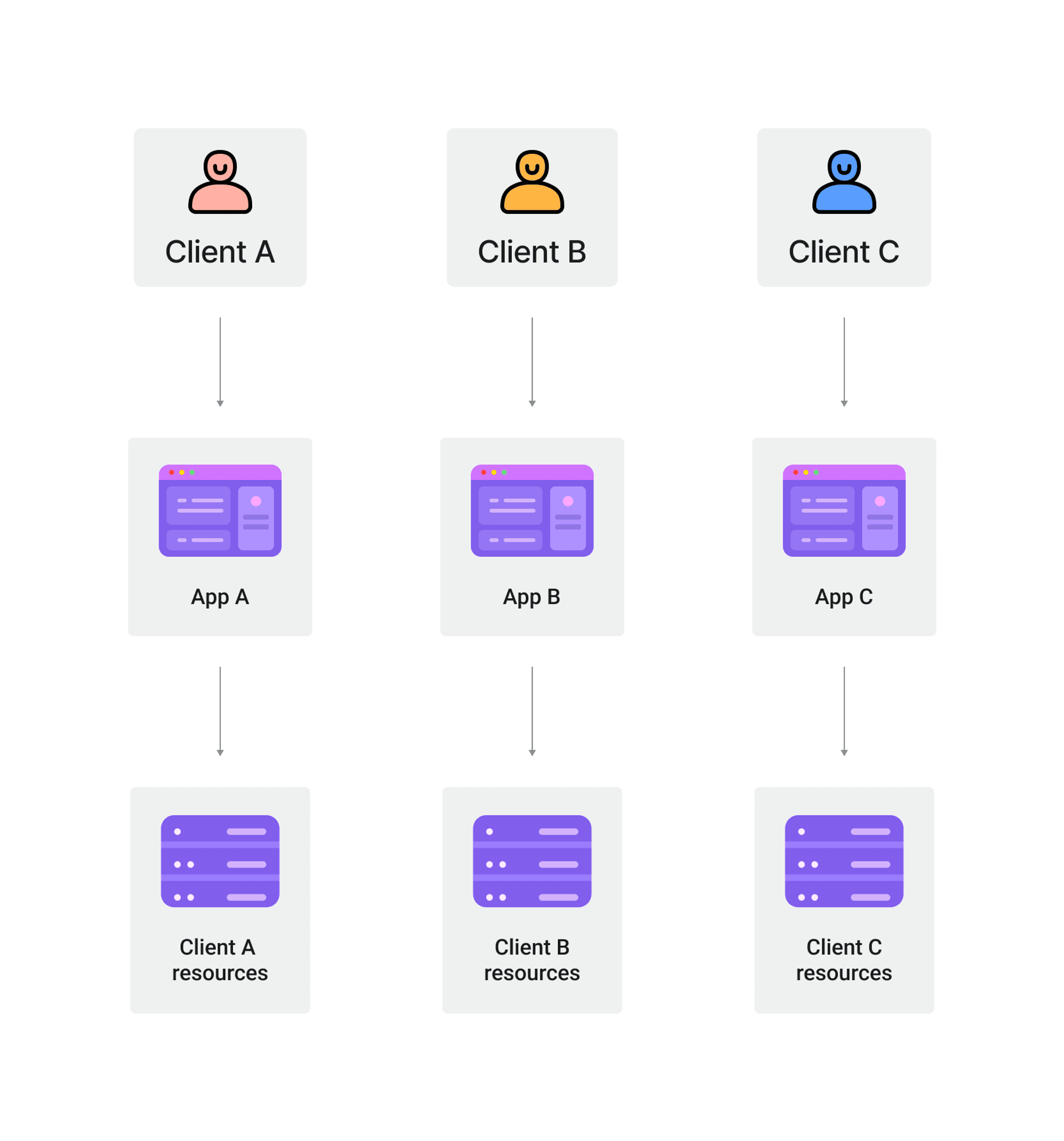
Was ist Single-Tenant-Architektur?
Single-Tenant-Architektur bezieht sich auf eine Softwarearchitektur, bei der jeder Kunde eine eigene dedizierte Instanz der Anwendung und Datenbank hat.
In dieser Architektur sind die Daten und Ressourcen jedes Mieters vollständig von anderen Mietern isoliert.
Was ist Multi-Tenant-Architektur?
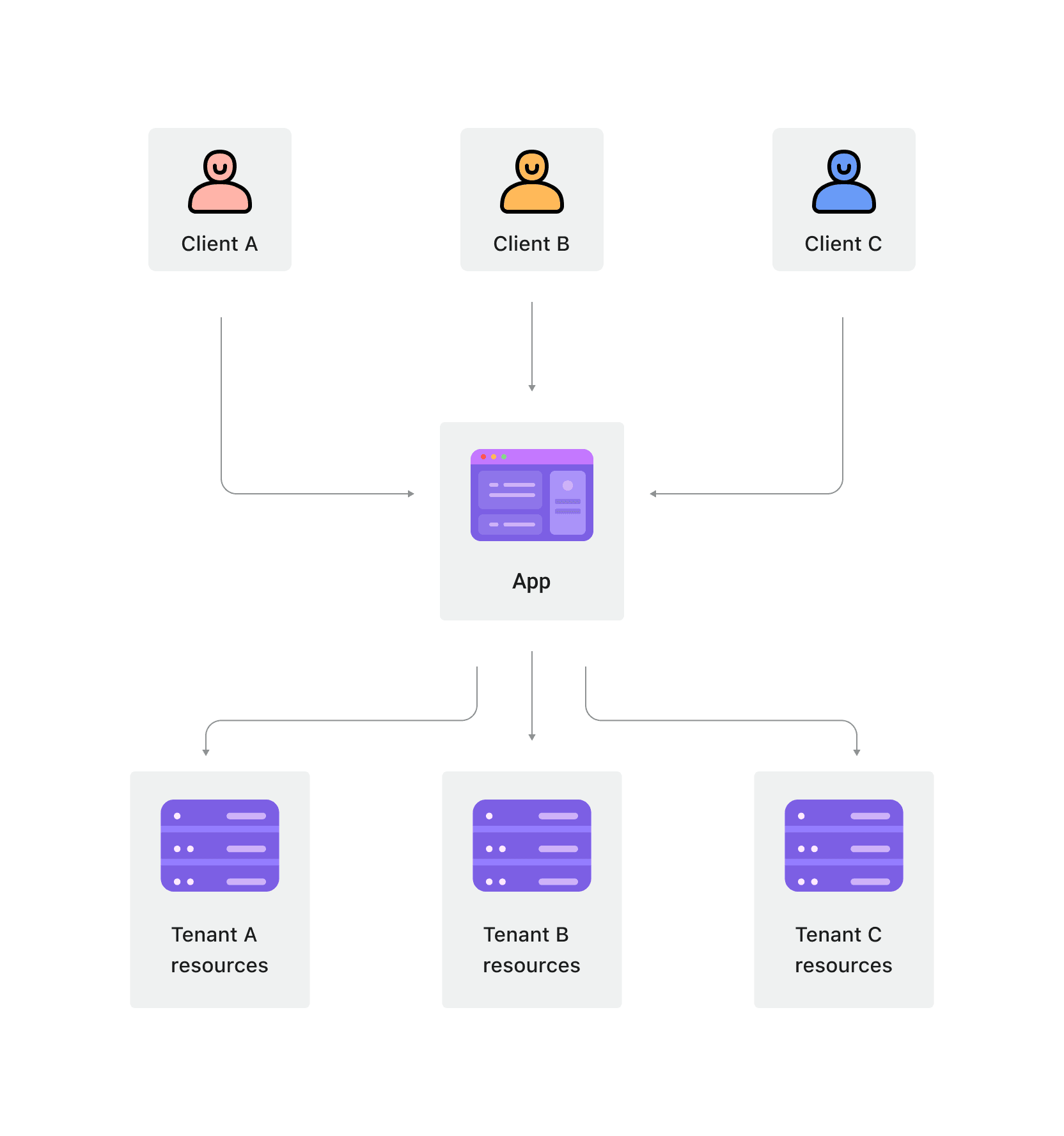
Multi-Tenant-Architektur ist eine Softwarearchitektur, bei der mehrere Kunden (Mieter) dieselbe Anwendungsinstanz und Infrastruktur teilen und dennoch Datenisolation beibehalten. In dieser Architektur dient eine einzige Instanz der Software mehreren Mietern, wobei die Daten jedes Mieters durch verschiedene Isolationsmechanismen von den anderen getrennt werden.
Single-Tenant-Architektur vs Multi-Tenant-Architektur
Single-Tenant-Architektur und Multi-Tenant-Architektur unterscheiden sich in Aspekten wie Datenisolation, Ressourcennutzung, Skalierbarkeit, Verwaltung und Wartung sowie Sicherheit.
In der Single-Tenant-Architektur hat jeder Kunde einen unabhängigen Datenbereich, was zu einer niedrigeren Ressourcenauslastung führt, jedoch relativ einfach für die Anpassung ist. Typischerweise ist die Single-Tenant-Software auf die spezifischen Bedürfnisse der Kunden zugeschnitten, wie z. B. Inventursysteme für einen bestimmten Stofflieferanten oder eine persönliche Blog-Webapp. Das Gemeinsame unter ihnen ist, dass jeder Kunde eine separate Instanz des Anwendungsdienstes belegt, was Anpassungen zur Erfüllung spezifischer Anforderungen erleichtert.
In einer Multi-Tenant-Architektur teilen mehrere Mieter dieselben zugrunde liegenden Ressourcen, was zu einer höheren Ressourcennutzung führt. Es ist jedoch entscheidend, Datenisolation und Sicherheit zu gewährleisten.
Multi-Tenant-Architektur ist oft die bevorzugte Softwarearchitektur, wenn Dienstanbieter standardisierte Dienste für verschiedene Kunden anbieten möchten. Diese Dienste haben normalerweise geringe Anpassungsgrade, und alle Kunden teilen dieselbe Anwendungsinstanz. Wenn eine Anwendung ein Update benötigt, ist das Aktualisieren einer Anwendungsinstanz gleichbedeutend mit dem Aktualisieren der Anwendung für alle Kunden. Beispielsweise ist CRM (Customer Relationship Management) eine standardisierte Anforderung. Diese Systeme verwenden typischerweise eine Multi-Tenant-Architektur, um denselben Dienst für alle Mieter bereitzustellen.
Strategien zur Datenisolation von Mietern in Multi-Tenant-Architektur
In einer Multi-Tenant-Architektur teilen alle Mieter dieselben zugrunde liegenden Ressourcen, weshalb die Isolierung von Ressourcen zwischen den Mietern entscheidend ist. Diese Isolierung muss nicht unbedingt physisch sein; es muss lediglich sichergestellt werden, dass Ressourcen zwischen den Mietern nicht sichtbar sind.
Im Design der Architektur können verschiedene Grade der Ressourcenisolierung zwischen Mietern erreicht werden:

Im Allgemeinen gilt: Je mehr Ressourcen zwischen den Mietern geteilt werden, desto niedriger sind die Kosten für die Systemiteration und -wartung. Umgekehrt gilt: Je weniger Ressourcen geteilt werden, desto höher sind die Kosten.
Beginn der Implementierung von Multi-Tenancy mit einem realen Beispiel
In diesem Artikel verwenden wir ein CRM-System als Beispiel, um eine einfache und dennoch praktische Multi-Tenant-Architektur vorzustellen.
Wir erkennen, dass alle Mieter dieselben Standarddienste nutzen, daher haben wir beschlossen, dass alle Mieter dieselben grundlegenden Ressourcen teilen sollen, und wir werden eine Datenisolation zwischen verschiedenen Mietern auf Datenbankebene mit der Row-Level-Security von PostgreSQL implementieren.
Zusätzlich werden wir für jeden Mieter eine separate Datenverbindung herstellen, um eine bessere Verwaltung der Mieterberechtigungen zu ermöglichen.
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape rect%2c%23mermaid-0 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg data-look='classic' id='Database' class='cluster'%3e%3crect height='332' width='281.640625' y='8' x='730.65625' style=''/%3e%3cg transform='translate(837.2265625%2c 8)' class='cluster-label'%3e%3cforeignObject height='24' width='68.5'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eDatabase%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg data-look='classic' id='subGraph0' class='cluster'%3e%3crect height='332' width='230.078125' y='8' x='254.046875' style=''/%3e%3cg transform='translate(321.96875%2c 8)' class='cluster-label'%3e%3cforeignObject height='24' width='94.234375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eCRM System%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_A_TA_0' d='M203.164%2c70L207.478%2c70C211.792%2c70%2c220.419%2c70%2c228.9%2c70C237.38%2c70%2c245.714%2c70%2c253.602%2c70C261.49%2c70%2c268.932%2c70%2c272.654%2c70L276.375%2c70'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_B_TB_1' d='M203.609%2c174L207.849%2c174C212.089%2c174%2c220.568%2c174%2c228.974%2c174C237.38%2c174%2c245.714%2c174%2c253.454%2c174C261.195%2c174%2c268.344%2c174%2c271.918%2c174L275.492%2c174'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_C_TC_2' d='M204.047%2c278L208.214%2c278C212.38%2c278%2c220.714%2c278%2c229.047%2c278C237.38%2c278%2c245.714%2c278%2c253.38%2c278C261.047%2c278%2c268.047%2c278%2c271.547%2c278L275.047%2c278'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TA_RDA_3' d='M457.797%2c70L462.185%2c70C466.573%2c70%2c475.349%2c70%2c500.281%2c70C525.214%2c70%2c566.302%2c70%2c607.391%2c70C648.479%2c70%2c689.568%2c70%2c713.759%2c70C737.951%2c70%2c745.245%2c70%2c748.892%2c70L752.539%2c70'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TB_RDB_4' d='M458.68%2c174L462.921%2c174C467.161%2c174%2c475.643%2c174%2c500.428%2c174C525.214%2c174%2c566.302%2c174%2c607.391%2c174C648.479%2c174%2c689.568%2c174%2c713.686%2c174C737.805%2c174%2c744.953%2c174%2c748.527%2c174L752.102%2c174'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_TC_RDC_5' d='M459.125%2c278L463.292%2c278C467.458%2c278%2c475.792%2c278%2c500.503%2c278C525.214%2c278%2c566.302%2c278%2c607.391%2c278C648.479%2c278%2c689.568%2c278%2c713.612%2c278C737.656%2c278%2c744.656%2c278%2c748.156%2c278L751.656%2c278'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(607.390625%2c 70)' class='edgeLabel'%3e%3cg transform='translate(-97.3828125%2c -12)' class='label'%3e%3cforeignObject height='24' width='194.765625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB-Verbindung f%c3%bcr Mieter A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(607.390625%2c 174)' class='edgeLabel'%3e%3cg transform='translate(-97.828125%2c -12)' class='label'%3e%3cforeignObject height='24' width='195.65625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB-Verbindung f%c3%bcr Mieter B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(607.390625%2c 278)' class='edgeLabel'%3e%3cg transform='translate(-98.265625%2c -12)' class='label'%3e%3cforeignObject height='24' width='196.53125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3cp%3eDB-Verbindung f%c3%bcr Mieter C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(369.0859375%2c 70)' id='flowchart-TA-0' class='node default'%3e%3crect height='54' width='177.421875' y='-27' x='-88.7109375' style='' class='basic label-container'/%3e%3cg transform='translate(-58.7109375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='117.421875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant A context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(369.0859375%2c 174)' id='flowchart-TB-1' class='node default'%3e%3crect height='54' width='179.1875' y='-27' x='-89.59375' style='' class='basic label-container'/%3e%3cg transform='translate(-59.59375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='119.1875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant B context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(369.0859375%2c 278)' id='flowchart-TC-2' class='node default'%3e%3crect height='54' width='180.078125' y='-27' x='-90.0390625' style='' class='basic label-container'/%3e%3cg transform='translate(-60.0390625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='120.078125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTenant C context%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(106.0234375%2c 70)' id='flowchart-A-3' class='node default'%3e%3crect height='54' width='194.28125' y='-27' x='-97.140625' style='' class='basic label-container'/%3e%3cg transform='translate(-67.140625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='134.28125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient von Mieter A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(106.0234375%2c 174)' id='flowchart-B-5' class='node default'%3e%3crect height='54' width='195.171875' y='-27' x='-97.5859375' style='' class='basic label-container'/%3e%3cg transform='translate(-67.5859375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='135.171875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient von Mieter B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(106.0234375%2c 278)' id='flowchart-C-7' class='node default'%3e%3crect height='54' width='196.046875' y='-27' x='-98.0234375' style='' class='basic label-container'/%3e%3cg transform='translate(-68.0234375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='136.046875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eClient von Mieter C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(871.4765625%2c 70)' id='flowchart-RDA-9' class='node default'%3e%3crect height='54' width='229.875' y='-27' x='-114.9375' style='' class='basic label-container'/%3e%3cg transform='translate(-84.9375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='169.875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eZeilendaten f%c3%bcr Mieter A%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(871.4765625%2c 174)' id='flowchart-RDB-10' class='node default'%3e%3crect height='54' width='230.75' y='-27' x='-115.375' style='' class='basic label-container'/%3e%3cg transform='translate(-85.375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='170.75'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eZeilendaten f%c3%bcr Mieter B%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(871.4765625%2c 278)' id='flowchart-RDC-11' class='node default'%3e%3crect height='54' width='231.640625' y='-27' x='-115.8203125' style='' class='basic label-container'/%3e%3cg transform='translate(-85.8203125%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='171.640625'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eZeilendaten f%c3%bcr Mieter C%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Als Nächstes werden wir erläutern, wie diese Multi-Tenant-Architektur implementiert wird.
Wie man Multi-Tenant-Architektur mit PostgreSQL implementiert
Fügen Sie für alle Ressourcen eine Mieterkennung hinzu
In einem CRM-System haben wir viele Ressourcen, die in verschiedenen Tabellen gespeichert sind. Beispielsweise werden Kundendaten in der Tabelle customers gespeichert.
Vor der Implementierung von Multi-Tenancy sind diese Ressourcen nicht mit einem Mieter verknüpft:
%3bopacity:0.7%3bbackground-color:hsl(80%2c 100%25%2c 96.2745098039%25)%3b%7d%23mermaid-1 .relationshipLabelBox rect%7bopacity:0.5%3b%7d%23mermaid-1 .relationshipLine%7bstroke:%23333333%3b%7d%23mermaid-1 .entityTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-1 %23MD_PARENT_START%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-1 %23MD_PARENT_END%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-1 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='240' markerWidth='190' refY='7' refX='0' id='MD_PARENT_START'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='19' id='MD_PARENT_END'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='0' id='ONLY_ONE_START'%3e%3cpath d='M9%2c0 L9%2c18 M15%2c0 L15%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='18' id='ONLY_ONE_END'%3e%3cpath d='M3%2c0 L3%2c18 M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='0' id='ZERO_OR_ONE_START'%3e%3ccircle r='6' cy='9' cx='21' fill='white' stroke='gray'/%3e%3cpath d='M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='30' id='ZERO_OR_ONE_END'%3e%3ccircle r='6' cy='9' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c0 L21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='18' id='ONE_OR_MORE_START'%3e%3cpath d='M0%2c18 Q 18%2c0 36%2c18 Q 18%2c36 0%2c18 M42%2c9 L42%2c27' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='27' id='ONE_OR_MORE_END'%3e%3cpath d='M3%2c9 L3%2c27 M9%2c18 Q27%2c0 45%2c18 Q27%2c36 9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='18' id='ZERO_OR_MORE_START'%3e%3ccircle r='6' cy='18' cx='48' fill='white' stroke='gray'/%3e%3cpath d='M0%2c18 Q18%2c0 36%2c18 Q18%2c36 0%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='39' id='ZERO_OR_MORE_END'%3e%3ccircle r='6' cy='18' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c18 Q39%2c0 57%2c18 Q39%2c36 21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cg transform='translate(20%2c20 )' id='entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530'%3e%3crect height='66' width='100' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(50%2c12)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530' class='er entityLabel'%3ecustomers%3c/text%3e%3crect height='21' width='49.71397399902344' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='50.28602600097656' y='24' x='49.71397399902344' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(54.71397399902344%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='49.71397399902344' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='50.28602600097656' y='45' x='49.71397399902344' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(54.71397399902344%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-name' class='er entityLabel'%3ename%3c/text%3e%3c/g%3e%3c/svg%3e)
Um die Mieter zu unterscheiden, die verschiedene Ressourcen besitzen, führen wir eine Tabelle tenants ein, um Mieterinformationen zu speichern (wobei db_user und db_user_password verwendet werden, um die Datenbankverbindungsinformationen für jeden Mieter zu speichern, was weiter unten detailliert wird). Zusätzlich fügen wir jeder Ressource ein tenant_id-Feld hinzu, um zu identifizieren, zu welchem Mieter sie gehört:
%3bopacity:0.7%3bbackground-color:hsl(80%2c 100%25%2c 96.2745098039%25)%3b%7d%23mermaid-2 .relationshipLabelBox rect%7bopacity:0.5%3b%7d%23mermaid-2 .relationshipLine%7bstroke:%23333333%3b%7d%23mermaid-2 .entityTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-2 %23MD_PARENT_START%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-2 %23MD_PARENT_END%7bfill:%23f5f5f5!important%3bstroke:%23333333!important%3bstroke-width:1%3b%7d%23mermaid-2 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='240' markerWidth='190' refY='7' refX='0' id='MD_PARENT_START'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='19' id='MD_PARENT_END'%3e%3cpath d='M 18%2c7 L9%2c13 L1%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='0' id='ONLY_ONE_START'%3e%3cpath d='M9%2c0 L9%2c18 M15%2c0 L15%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='18' refY='9' refX='18' id='ONLY_ONE_END'%3e%3cpath d='M3%2c0 L3%2c18 M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='0' id='ZERO_OR_ONE_START'%3e%3ccircle r='6' cy='9' cx='21' fill='white' stroke='gray'/%3e%3cpath d='M9%2c0 L9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='18' markerWidth='30' refY='9' refX='30' id='ZERO_OR_ONE_END'%3e%3ccircle r='6' cy='9' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c0 L21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='18' id='ONE_OR_MORE_START'%3e%3cpath d='M0%2c18 Q 18%2c0 36%2c18 Q 18%2c36 0%2c18 M42%2c9 L42%2c27' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='45' refY='18' refX='27' id='ONE_OR_MORE_END'%3e%3cpath d='M3%2c9 L3%2c27 M9%2c18 Q27%2c0 45%2c18 Q27%2c36 9%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='18' id='ZERO_OR_MORE_START'%3e%3ccircle r='6' cy='18' cx='48' fill='white' stroke='gray'/%3e%3cpath d='M0%2c18 Q18%2c0 36%2c18 Q18%2c36 0%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='36' markerWidth='57' refY='18' refX='39' id='ZERO_OR_MORE_END'%3e%3ccircle r='6' cy='18' cx='9' fill='white' stroke='gray'/%3e%3cpath d='M21%2c18 Q39%2c0 57%2c18 Q39%2c36 21%2c18' fill='none' stroke='gray'/%3e%3c/marker%3e%3c/defs%3e%3cg transform='translate(20%2c20 )' id='entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e'%3e%3crect height='87' width='131.66140747070312' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(65.83070373535156%2c12)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e' class='er entityLabel'%3etenants%3c/text%3e%3crect height='21' width='35.245819091796875' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='24' x='35.245819091796875' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c34.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='35.245819091796875' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='45' x='35.245819091796875' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c55.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-2-name' class='er entityLabel'%3edb_user%3c/text%3e%3crect height='21' width='35.245819091796875' y='66' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c76.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-3-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='96.41558837890625' y='66' x='35.245819091796875' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(40.245819091796875%2c76.5)' y='0' x='0' id='text-entity-tenants-56b5c3c6-4585-5857-96ff-f027447cdf2e-attr-3-name' class='er entityLabel'%3edb_user_password%3c/text%3e%3c/g%3e%3cg transform='translate(251.66140747070312%2c20 )' id='entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530'%3e%3crect height='87' width='100' y='0' x='0' class='er entityBox'/%3e%3ctext style='dominant-baseline: middle%3b text-anchor: middle%3b font-family: arial%2c sans-serif%3b font-size: 12px%3b' transform='translate(50%2c12)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530' class='er entityLabel'%3ecustomers%3c/text%3e%3crect height='21' width='41.49632263183594' y='24' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='24' x='41.49632263183594' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c34.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-1-name' class='er entityLabel'%3eid%3c/text%3e%3crect height='21' width='41.49632263183594' y='45' x='0' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='45' x='41.49632263183594' class='er attributeBoxEven'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c55.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-2-name' class='er entityLabel'%3ename%3c/text%3e%3crect height='21' width='41.49632263183594' y='66' x='0' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(5%2c76.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-3-type' class='er entityLabel'%3estring%3c/text%3e%3crect height='21' width='58.50367736816406' y='66' x='41.49632263183594' class='er attributeBoxOdd'/%3e%3ctext style='dominant-baseline: middle%3b font-family: arial%2c sans-serif%3b font-size: 10.2px%3b' transform='translate(46.49632263183594%2c76.5)' y='0' x='0' id='text-entity-customers-81c4bf60-f037-5ffd-bea1-c082debbd530-attr-3-name' class='er entityLabel'%3etenant_id%3c/text%3e%3c/g%3e%3c/svg%3e)
Jetzt ist jede Ressource mit einer tenant_id verknüpft, wodurch wir theoretisch in der Lage sind, eine where-Klausel zu allen Abfragen hinzuzufügen, um den Zugriff auf Ressourcen für jeden Mieter einzuschränken:
Auf den ersten Blick scheint dies einfach und machbar. Es wird jedoch die folgenden Probleme haben:
- Fast jede Abfrage enthält diese
where-Klausel, was den Code überladen und schwer wartbar macht, insbesondere bei komplexen Join-Anweisungen. - Neue Mitarbeiter im Codebestand könnten leicht vergessen, diese
where-Klausel hinzuzufügen. - Daten zwischen verschiedenen Mietern sind nicht wirklich isoliert, da jeder Mieter immer noch Berechtigungen hat, auf die Daten anderer Mieter zuzugreifen.
Daher werden wir diesen Ansatz nicht verfolgen. Stattdessen werden wir die Row-Level-Security von PostgreSQL verwenden, um diese Bedenken anzugehen. Bevor wir fortfahren, werden wir jedoch für jeden Mieter ein dediziertes Datenbankkonto erstellen, um auf diese freigegebene Datenbank zuzugreifen.
DB-Rollen für Mieter einrichten
Es ist eine gute Praxis, jedem Benutzer, der sich mit der Datenbank verbinden kann, eine Datenbankrolle zuzuordnen. Dies ermöglicht eine bessere Kontrolle über den Datenbankzugriff jedes Benutzers, erleichtert die Isolierung von Operationen zwischen verschiedenen Benutzern und verbessert die Stabilität und Sicherheit des Systems.
Da alle Mieter die gleichen Datenbankberechtigungen haben, können wir eine Basisrolle erstellen, um diese Berechtigungen zu verwalten:
Um jede Mieterrolle zu differenzieren, wird jedem Mieter bei der Erstellung eine von der Basisrolle abgeleitete Rolle zugewiesen:
Als Nächstes werden die Datenbankverbindungsinformationen für jeden Mieter in der Tabelle tenants gespeichert:
| id | db_user | db_user_password |
|---|---|---|
| x2euic | crm_tenant_x2euic | pa55w0rd |
Dieser Mechanismus bietet jedem Mieter seine eigene Datenbankrolle, und diese Rollen teilen die Berechtigungen, die der Rolle crm_tenant gewährt wurden.
Wir können dann den Berechtigungsumfang für Mieter mithilfe der Rolle crm_tenant definieren:
- Mieter sollten Lese- und Schreibzugriff auf alle Ressourcen-Tabellen des CRM-Systems haben.
- Tabellen, die nicht mit den Ressourcen des CRM-Systems in Zusammenhang stehen, sollten für die Mieter unsichtbar sein (angenommen, nur die Tabelle
systems). - Mieter sollten die Tabelle
tenantsnicht ändern können, und nur die Felderidunddb_usersollten ihnen angezeigt werden, damit sie ihre eigene Mieter-ID abfragen können, wenn sie Datenbankoperationen durchführen.
Sobald die Rollen für Mieter eingerichtet sind, können wir bei einer Anfrage eines Mieters auf den Dienst mit der Datenbankrolle, die diesen Mieter repräsentiert, mit der Datenbank interagieren:
%3bfill:%23ECECFF%3b%7d%23mermaid-3 text.actor%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .actor-line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-3 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-3 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-3 %23arrowhead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-3 .sequenceNumber%7bfill:white%3b%7d%23mermaid-3 %23sequencenumber%7bfill:%23333%3b%7d%23mermaid-3 %23crosshead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-3 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-3 .labelBox%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-3 .labelText%2c%23mermaid-3 .labelText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .loopText%2c%23mermaid-3 .loopText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-3 .note%7bstroke:%23aaaa33%3bfill:%23fff5ad%3b%7d%23mermaid-3 .noteText%2c%23mermaid-3 .noteText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-3 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-3 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-3 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23ECECFF%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-3 .actor-man line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-3 .actor-man circle%2c%23mermaid-3 line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3bstroke-width:2px%3b%7d%23mermaid-3 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol height='24' width='24' id='computer'%3e%3cpath d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol clip-rule='evenodd' fill-rule='evenodd' id='database'%3e%3cpath d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol height='24' width='24' id='clock'%3e%3cpath d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto-start-reverse' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='7.9' id='arrowhead'%3e%3cpath d='M -1 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker refY='4.5' refX='4' orient='auto' markerHeight='8' markerWidth='15' id='crosshead'%3e%3cpath style='stroke-dasharray: 0%2c 0%3b' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' stroke-width='1pt' stroke='black' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='15.5' id='filled-head'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='40' markerWidth='60' refY='15' refX='15' id='sequencenumber'%3e%3ccircle r='6' cy='15' cx='15'/%3e%3c/marker%3e%3c/defs%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='80' x='290'%3eFordere Ressourcen von Mieter A mit %60tenant_id_a%60%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='111' x2='504' y1='111' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='126' x='834'%3eRufe Mieter-DB-Zugangsdaten ab mit %60tenant_id_a%60%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='157' x2='1159' y1='157' x1='509'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='172' x='837'%3eDB-Zugangsdaten f%c3%bcr Mieter A%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='201' x2='512' y1='201' x1='1162'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='216' x='834'%3eStelle eine DB-Verbindung f%c3%bcr Mieter A mit den DB-Zugangsdaten von Mieter A her%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='245' x2='1159' y1='245' x1='509'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='260' x='837'%3eDB-Verbindung f%c3%bcr Mieter A%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='289' x2='512' y1='289' x1='1162'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='304' x='834'%3eRufe Ressourcen von Mieter A %c3%bcber die DB-Verbindung von Mieter A ab%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='333' x2='1159' y1='333' x1='509'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='348' x='837'%3eRessourcen von Mieter A%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='377' x2='512' y1='377' x1='1162'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='392' x='293'%3eRessourcen von Mieter A%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='421' x2='79' y1='421' x1='507'/%3e%3c/svg%3e)
Sicherung der Mieterdaten mit PostgreSQL Row-Level Security
Bisher haben wir entsprechende Datenbankrollen für Mieter eingerichtet, aber dies beschränkt nicht den Datenzugriff zwischen den Mietern. Als Nächstes werden wir die Row-Level-Security-Funktion von PostgreSQL nutzen, um den Zugriff jedes Mieters nur auf seine eigenen Daten zu beschränken.
In PostgreSQL können Tabellen Zeilensicherheitspolicen haben, die steuern, welche Reihen von Abfragen abgerufen oder durch Datenmanipulationsbefehle geändert werden können. Diese Funktion ist auch bekannt als RLS (Row-Level Security).
Standardmäßig haben Tabellen keine Zeilensicherheitspolicen. Um RLS zu nutzen, müssen Sie es für die Tabelle aktivieren und Sicherheitspolicen erstellen, die jedes Mal ausgeführt werden, wenn auf die Tabelle zugegriffen wird.
Am Beispiel der Tabelle customers im CRM-System werden wir RLS aktivieren und eine Sicherheitspolice erstellen, um den Zugriff jedes Mieters nur auf seine eigenen Kundendaten zu beschränken:
In der Anweisung zur Erstellung der Sicherheitspolice:
for all(optional) gibt an, dass diese Zugangspolice fürselect-,insert-,update- unddelete-Operationen auf die Tabelle verwendet wird. Sie können eine Zugangspolice für bestimmte Operationen spezifizieren, indem Sieforgefolgt vom Befehlskeyword verwenden.to crm_tenantgibt an, dass diese Police für Benutzer mit der Datenbankrollecrm_tenantgilt, also alle Mieter.as restrictivelegt den Durchsetzungsmodus der Police fest und gibt an, dass der Zugang streng limitiert sein sollte. Standardmäßig kann eine Tabelle mehrere Policen haben, mehrerepermissivePolicen werden mit einerORBeziehung kombiniert. In diesem Szenario deklarieren wir diese Police alsrestrictive, weil wir möchten, dass diese Police-Prüfung obligatorisch für Benutzer ist, die zu CRM-Systemmietern gehören.usingAusdruck definiert die Bedingungen für den tatsächlichen Zugang und beschränkt den aktuellen abfragenden Datenbankbenutzer darauf, nur Daten zu sehen, die zu seinem jeweiligen Mieter gehören. Diese Einschränkung gilt für Zeilen, die von einem Befehl (select,updateoderdelete) ausgewählt werden.with checkAusdruck definiert die notwendige Einschränkung beim Ändern von Datenzeilen (insertoderupdate) und garantiert, dass Mieter nur Einträge für sich selbst hinzufügen oder aktualisieren können.
Die Verwendung von RLS zur Einschränkung des Mietzugriffs auf unsere Ressourcentabellen bietet mehrere Vorteile:
- Diese Police fügt effektiv
where tenant_id = (select id from tenants where db_user = current_user)zu allen Abfrageoperationen hinzu (select,updateoderdelete). Wenn Sie beispielsweiseselect * from customersausführen, wird dies äquivalent zuselect * from customers where tenant_id = (select id from tenants where db_user = current_user). Dies eliminiert die Notwendigkeit,where-Bedingungen im Anwendungscode explizit hinzuzufügen, vereinfacht ihn und reduziert die Wahrscheinlichkeit von Fehlern. - Sie kontrolliert zentral die Datenzugriffsberechtigungen zwischen verschiedenen Mietern auf Datenbankebene und mindert das Risiko von Schwachstellen oder Inkonsistenzen in der Anwendung, wodurch die Systemsicherheit verbessert wird.
Es gibt jedoch einige Punkte zu beachten:
- RLS-Policen werden für jede Datenzeile ausgeführt. Wenn die Abfragebedingungen innerhalb der RLS-Police zu komplex sind, könnte dies die Systemleistung erheblich beeinträchtigen. Glücklicherweise ist unsere Abfrage zur Überprüfung der Mandantendaten einfach genug und wird die Leistung nicht beeinträchtigen. Wenn Sie planen, später andere Funktionen mit RLS zu implementieren, können Sie den Empfehlungen zur Performance von Row-Level Security von Supabase folgen, um die RLS-Performance zu optimieren.
- RLS-Policen füllen
tenant_idnicht automatisch währendinsert-Operationen auf. Sie beschränken Mieter nur auf das Einfügen ihrer eigenen Daten. Das bedeutet, dass wir beim Einfügen von Daten immer noch die Mieter-ID angeben müssen, was inkonsistent mit dem Abfrageprozess ist und während der Entwicklung zu Verwirrung führen und die Wahrscheinlichkeit von Fehlern erhöhen kann (dies wird in den nächsten Schritten behandelt).
Zusätzlich zur Tabelle customers müssen wir die gleichen Operationen auf alle Ressourcen-Tabellen des CRM-Systems anwenden (dieser Prozess kann etwas mühsam sein, aber wir können ein Programm schreiben, um dies bei der Initialisierung der Tabellen zu konfigurieren), um so die Daten der verschiedenen Mieter zu isolieren.
Trigger-Funktion für das Einfügen von Daten erstellen
Wie bereits erwähnt, ermöglicht es uns RLS (Row-Level-Security), Abfragen auszuführen, ohne uns um die Existenz von tenant_id sorgen zu müssen, da die Datenbank dies automatisch handhabt. Für insert-Operationen müssen wir jedoch immer noch manuell die entsprechende tenant_id angeben.
Um ein ähnliches Maß an Bequemlichkeit wie RLS für das Einfügen von Daten zu erreichen, muss die Datenbank in der Lage sein, tenant_id beim Einfügen von Daten automatisch zu handhaben.
Dies hat einen klaren Vorteil: Auf der Ebene der Anwendungsentwicklung müssen wir uns keine Gedanken mehr darüber machen, zu welchem Mieter die Daten gehören, was die Wahrscheinlichkeit von Fehlern verringert und die mentale Belastung beim Entwickeln von Multi-Tenant-Anwendungen verringert.
Glücklicherweise bietet PostgreSQL leistungsstarke Trigger-Funktionalitäten.
Trigger sind spezielle Funktionen, die mit Tabellen verknüpft sind und automatisch bestimmte Aktionen (wie Einfügen, Aktualisieren oder Löschen) ausführen, wenn sie auf die Tabelle angewendet werden. Diese Aktionen können auf Zeilenebene (für jede Zeile) oder Anweisungsebene (für die gesamte Anweisung) ausgelöst werden. Mit Triggern können wir benutzerdefinierte Logik vor oder nach bestimmten Datenbankoperationen ausführen, wodurch wir unser Ziel leicht erreichen können.
Erstellen wir zunächst eine Trigger-Funktion set_tenant_id, die vor jedem Einfügen von Daten ausgeführt wird:
Als Nächstes verknüpfen wir diese Trigger-Funktion mit der Tabelle customers für Insert-Operationen (ähnlich wie das Aktivieren von RLS für eine Tabelle, muss diese Trigger-Funktion mit allen relevanten Tabellen verknüpft werden):
Dieser Trigger stellt sicher, dass eingefügte Daten das korrekte tenant_id enthalten. Wenn die neuen Daten bereits ein tenant_id enthalten, tut die Trigger-Funktion nichts. Andernfalls füllt sie das tenant_id-Feld automatisch basierend auf den Informationen des aktuellen Benutzers in der Tabelle tenants aus.
So erreichen wir die automatische Handhabung von tenant_id auf Datenbankebene während des Einfügens von Daten durch Mieter.
Zusammenfassung
In diesem Artikel befassen wir uns mit der praktischen Anwendung von Multi-Tenant-Architekturen und verwenden ein CRM-System als Beispiel, um eine praktische Lösung mithilfe der PostgreSQL-Datenbank aufzuzeigen.
Wir diskutieren die Verwaltung von Datenbankrollen, den Zugriffskontrollmechanismen und die Row-Level-Security-Funktion von PostgreSQL, um die Datenisolation zwischen Mietern zu gewährleisten. Außerdem nutzen wir Trigger-Funktionen, um die kognitive Belastung der Entwickler bei der Verwaltung verschiedener Mieter zu reduzieren.
Das war's für diesen Artikel. Wenn Sie Ihre Multi-Tenant-Anwendung mit dem Benutzerzugangsmanagement weiter verbessern möchten, können Sie Eine einfache Anleitung, um mit Logto-Organisationen zu beginnen - für den Aufbau einer Multi-Tenant-App für weitere Einblicke konsultieren.